JavaScript中的对象和继承
对象
对象:无序属性的集合,其属性可以包含基本值、对象或者函数
JavaScript中的对象和其他OO(Object-Oriented,面向对象)语言不大相同。它没有类的概念。所以根据ECMAScript的定义,对象无非就是一组键值对,类似于散列(Hash)表的概念,其中的值可以是基本类型也可以是对象或函数。
一个常见的对象像下面这样
1 | var Stu = new Object(); |
对象属性
对象属性(property)是实现JavaScript引擎用的,由两对方括号包裹,表示是内部值,如[[Enumerable]]。ECMAScript中目前分两种属性:数据属性和访问器属性。
数据属性
[[Configurable]]: 表示能否通过delete删除属性,能否修改属性。默认为true。[[Enumerable]]: 能否通过for-in语句循环返回属性。默认为true。[[Writable]]: 如同字面意思,能否修改属性的值。[[Value]]: 属性的数据值。
数据属性可以直接通过字面量来定义。可以通过ECMAScript 5中Object.defineProperty()方法修改对象默认属性。方法接受三个参数:属性所在对象,属性名,和一个描述符对象。其中描述符对象的属性必须是上述4个属性的子集。值得注意的是,修改configurable为false后,将无法将其变为true。此时,只能修改writable和value。
在使用Object.defineProperty()创建新属性时,若不指定,前三项的属性默认均为false。
访问器属性
访问器属性不包含数据值(即value),取而代之的是getter和setter两个函数。不过它们也不是必须的。
[[Configurable]]: 表示能否通过delete删除属性,能否修改属性。默认为true。[[Enumerable]]: 能否通过for-in语句循环返回属性。默认为true。[[Get]]: 读取属性时调用的函数,默认为undefined[[Set]]: 写入属性时调用的函数,默认为undefined
访问器属性不能直接定义。必须使用Object.defineProperty()方法定义。未指定getter或setter时,意味着属性不可读或不可写。强制读写时,在严格模式下会抛出错误,非严格模式下会返回undefined。
1 | var person = { |
访问器属性实际上使得数据劫持得以实现,即在存取属性值时执行预定义的操作。Vue的数据绑定就是这么来实现的(具体的实现方式见另外的博文)。不过支持Object.defineProperty()方法的浏览器需要IE9+,Firefox4+,Safari5+,Opera12+,Chrome。在这个方法前,通常使用两个非规范的方法__defineGetter__()和__defineSetter__(),它们是对象的prototype中的的方法。
ECMAScript 5还定义了一个Object.defineProperties()方法,用于为对象定义多个属性。用法如下:
1 | var person = {}; |
读取属性的特性
Object.getOwnPropertyDescriptor()方法可以读取指定对象属性的描述符。如果属性是数据属性,则返回对象包含configurable, enumerable, writable, value;如果属性是访问器属性,则返回对象包括configurable, enumerable, get, set。支持这个方法的浏览器包括IE9+,Firefox4+,Safari5+,Opera12+,Chrome。
创建对象
最简单的创建方法是通过Object构造函数和字面量的形式,如第一段代码里展示的那样。不过很显然,这么做有点蠢。在创建大量对象的时候,会产生成吨的重复代码。于是就产生了下面这些工程手段。
工厂模式
既然会产生重复代码,那么将这些重复代码封装成函数不就行了么。工厂模式就这么出现了。
1 | function createPerson (name, age, school) { |
这么做解决了创建相似对象的问题,不过并没解决对象识别的问题。而且可以复用的函数创建了很多次。
构造函数模式
ECMAScript中的构造函数可用来创建特定类型的对象,从而解决了对象识别的问题。上面的例子用构造函数模式重写如下:
1 | function Person (name, age, school) { |
通过构造函数创建实例时,需要使用new操作符。创建的步骤如下:
- 创建一个空对象
- 将构造函数的作用域(this)赋给空对象
- 执行函数代码
- 返回这个对象
1 | p1.constructor == Person //true |
返回对象会自带constructor属性,指向构造函数本身。可以用来区分对象类型。不过使用instanceof操作符要更可靠些。因为构造函数本身也是函数,只是用来构造对象而已。为了和其他函数区分开,通常命名首字母使用大写字母。这么做是为了避免一个问题:当不使用new操作符调用构造函数时,函数作用域并不会指向新创建的函数,因此this实际上是进入函数时的全局作用域,从而会污染全局作用域。
可以看到一个问题,使用构造函数模式并未解决函数复用的目标,同样的函数创建了许多次,通过p1.sayHi == p2.sayHi //false即可发现。为了复用函数,可以把函数放在构造函数外。
1 | function Person (name, age, school) { |
这么做却又带来了副作用,全局作用域中定义的函数,实际上只能被函数调用。且不同对象的方法作为全局函数混杂在一起,封装性很差劲。
原型模式
原型(prototype)的设计解决了这个大问题。每个函数都有一个prototype属性。这个属性是一个指针,指向一个对象,包含由该函数构造对象共享的属性和方法。从而,不必在构造函数中定义所有实例共有的属性和方法。
1 | function Person () {}; |
原型对象
无论何时,只要创建了一个新函数,就会相应的为该函数创建一个prototype属性,指向该函数的原型对象。默认情况下,所有原型对象都会有一个constructor属性指向prototype属性所在函数。
创建自定义的构造函数时,原型对象默认只会有constructor属性,其他的方法都继承自Object。在调用构造函数创建对象实例后,实例的内部都有一个指针[[prototype]]指向构造函数的原型对象。这个指针是内部的,但在FF,Safari,Chrome中,有__proto__属性可以访问。
是不是听起来有点晕,下面的图(来自红宝书)形象地说明了上面这些关系。
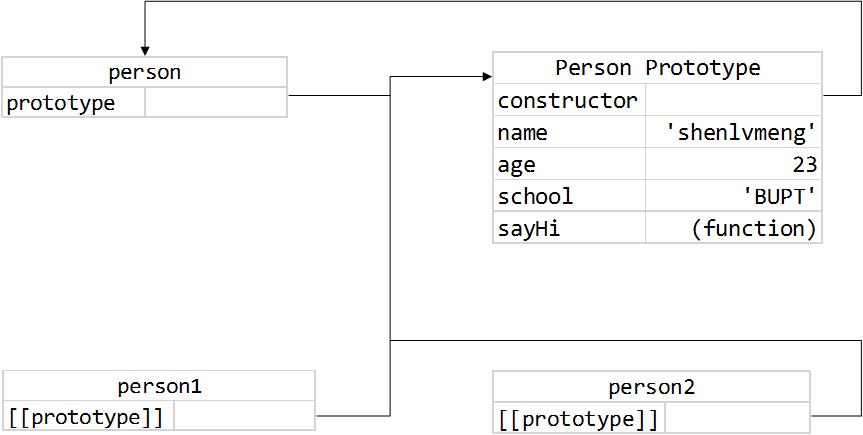
虽然无法访问到[[prototype]]属性,但是可以通过prototype的isPrototypeOf()方法确认对象和原型的对应关系,或ES5中的Object.prototype()得到[[prototype]]的值。
代码在尝试读取对象属性的时候,会先从实例本身属性开始,若找到同名属性,则返回值;如果没有找到,则继续搜索指针指向的原型对象。例如,因为原型对象中包含constructor属性,所以实际上对象实例也都可以访问到constructor这个属性。在为对象实例添加属性时,这个属性会屏蔽(不是覆盖)原型对象中的同名属性。通过对象的hasOwnProperty()方法,可以检测属性来自实例还是原型对象。
in 操作符
in操作有两种使用方法,单独使用和配合for-in循环使用。前者在对象可以访问给定属性时返回true。
1 | alert(p1.hasOwnProperty('name')); //false |
for-in循环可以访问所有对象可以访问的、可枚举(enumerable)的属性。既包含实例自身属性,也包含原型中的属性。下面是个简单的例子。
1 | var body = document.body.attributes; |
使用最新的Object.keys()可以获取所有键名,使用Object.getOwnPropertyNames()方法可以返回所有实例属性,而不论是否可枚举。
重写prototype
上面原型模式里一个一个属性为prototype赋值的方法略显重复,可以直接通过对象字面量的形式重写整个原型对象。但是需要注意的是,重写后的原型对象中的constructor属性继承自Object。此时只能通过instanceof操作符确定对象类型了。
1 | function Person () {}; |
因为在原型中查找值是一次搜索的过程,我们对原型对象所做的修改都会立即在对象中体现出来。
问题
原型对象中的所有属性和方法都在实例中共享,这在某些场景下可能并不是我们想要的。比如,不同的Person间应该总有些自己的属性。这些应该在构造函数中体现出来。
组合使用构造函数和原型模式
如上面所说,将实例的属性放在构造函数中,将共有属性和方法放在原型对象中,可以最大程度减少无谓的内存占用。因此,这也是目前使用最多的创建自定义类型的方法。
1 | function Person (name, age, school) { |
其他
寄生构造函数和稳妥构造函数在有些时候也用来构造对象。前者仅仅将创建对象的代码封装起来,通过new操作符调用,内部不使用this。这种情况下,对象和构造函数实际上没有关系,因此不能使用instanceof操作符确定类型。
稳妥构造函数有Douglas Crockford提出,利用了闭包的特点,保证了内部数据的安全性和封装性。函数内部没有公共属性,也不引用this对象。
1 | function Person (name, age, school) { |
继承
传统面向对象语言支持继承接口和继承实现。前者只继承签名,实现接口;后者继承实现的方法。ECMAScript只支持后者(ECMAScript中没有函数签名)。其实现主要利用原型链。
原型链
ECMAScript中最基本的继承方式,它的思想在于通过原型让一个自定义类型用于另一个类型的属性和方法。具体实现上,只用将一个对象实例作为另一个对象的原型对象即可。
1 | //父类 |
上面的关键一步就是将父类的实例赋给子类的prototype,从而子类的所有实例可以共享父类的所有属性和方法。在上面的步骤中,SubType默认的原型被替换为SuperType的实例,所以实际上,SubType的constructor属性成为了SuperType。这是因为,再找不到属性或方法时,搜索过程会一步一步向原型链末端前进,直到Object。
下面是SuperType和SubType构造函数以及原型对象间的关系。
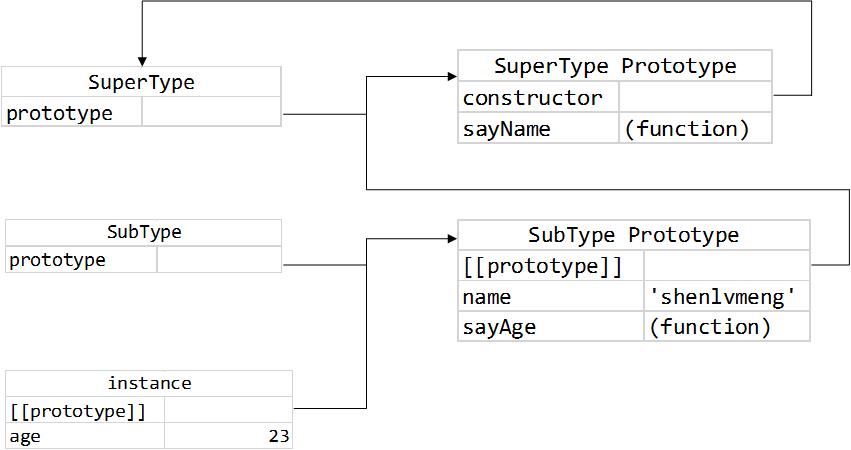
可以发现,使用原型链的一个问题是,父类的实例属性变成了子类的原型属性,分享在子类所有实例间。很显然是不合理的。第二,创建子类型时,为超类构造函数传递的参数将作为原型对象影响整个子类对象实例。
借用构造函数
这种方法的思路是,在子类构造函数调用父类的构造函数,并将执行环境绑定在子类环境中。这样可以方便地向父类构造函数中添加自己的参数而不影响其他的子类实例。
1 | function SuperType (newFriend) { |
这么做的缺点也很明显,函数的定义都需要在构造函数中重新写一遍。因此,这种技术很少单独使用。
组合继承
组合继承发挥了上面两者的长处,通过原型链继承了原型属性和方法,通过构造函数实现对父类实例属性的继承。
1 | function SuperType (newFriend) { |
组合继承是JavaScript中最常用的集成模式。不过它实际上调用了两次父类的构造函数,因此后面介绍的寄生组合式继承方法又对此进行了优化。
原型式继承
Douglas CrockFord在2006年提出可以通过原型基于已有对象创建新对象,还不必创建自定义类型。函数大概像下面这样
1 | function object(o) { |
可以看到,本质上,object函数只是对传入的对象o进行了一层浅复制。从而其中的引用类型将会在返回的对象间共享。ECMAScript 5对这种通过对象创建对象的原型式继承方式进行了规范,新增了Object.create()方法。方法接受两个参数,一个作为新对象原型,一个作为新对象新增的额外属性。
寄生式继承模式和原型式继承很类似。它将创建一个仅用来封装继承过程的函数,在函数内部处理增强对象的过程。功能和Object.create()类似。但是这么做不能做到函数复用,从而效率会降低,用在简单的场景下。
寄生组合式继承
这种模式解决了组合式继承的弊端——调用两次父类构造函数。其中SubType构造函数中的调用作为实例的属性将覆盖原型中的同名属性。寄生组合式继承的关键在于:不必为了指定子类型的原型而调用父类的构造函数,我们不过是要一个父类原型的副本而已。因此,可以得到下面这样的基本模式:
1 | function inheritPrototype (subtype, supertype) { |
上面的三步分别是创建对象,添加constructor属性,替换子类原型。从而在继承的过程中只调用了1次SuperType函数。同时原型链保持了不变。因此insanceof和isPrototypeOf()可以正常使用。寄生组合式继承是最理想的继承模式。就像下面这样。
1 | function SuperType (newFriend) { |
总结
总结一下,ECMAScript支持面向对象编程,但没有类和接口的概念。对象和原型的定义和关系比较松散。
在创建对象上,有工厂模式、原型对象、构造函数、利用闭包几种方式可选,它们也可以组合使用。
在实现继承上,可以借助原型链、构造函数和寄生组合式的模式实现比较严格的继承,原型式和寄生式模式用于不那么严格的对象间继承。
