Elm——函数式前端框架介绍
前言
Elm提出于2012年,最初出现在Evan Czaplicki的毕业论文中(掩面)。目标是提出一个面向web的函数式编程语言。它拥有诸多特性
- 强类型语言
- 一次编译,no runtime error
- 状态不可修改
- 函数是一级公民等
Elm是门新语言,它是一个类似React(但绝对和它不一样)的前端框架。在Web App的设计它甚至启发了Flux设计的提出。在如今前端框架吸收函数式编程以及强类型语言优点的形势下,学习Elm可能会开启对Web前端开发的重新认识。
再看完下面的介绍后,建议阅读两篇对Elm的评价,相信更有助于对这门年轻语言特点的理解:
准备工作
Elm是通过将代码编译成JavaScript工作的。一个最简单的Elm App大概像下面这样:
1 | import Html exposing (Html, button, div, text) |
那么这样一个Elm文件是怎么应用在页面中呢?
在Elm安装完成后,会有4个Elm相关的包:
- elm-repl 命令行操作,在cli中感受Elm的语法特点
- elm-reactor 快速脚手架搭建
- elm-make 编译工具
- elm-package 包管理工具
麻雀虽小,五脏俱全。
语法特点
Elm在语法上不同于C风格的所有语言,和Haskell更为靠近。
注释
用--开启单行注释,结合{}进行多行注释
1 | -- a single line comment |
类型
Elm是强类型语言,有Bool,Int,Float,Char,String 5种基本类型。有意思的是,Elm没有Null。这也是特别设计的。
除了基本类型,Elm中还有List,Array,Tuple,Dict,Record几种泛型。其中List,Record设计类似JavaScript中的Array和Object。
1 | [1,2,3,4] |
*(值得注意的是,上面的::和.x实际上都是函数)*。
类型声明
类型是Elm中重要的一环,每个变量都需要有类型,编译时需要进行检查。因此显式地声明变量类型很重要。
当我们需要通过基本类型构造复杂类型时,可以通过type alias的形式为record创建新的类型。在新类型创建的同时,会同步生成一个record构造函数。
1 | -- Before:麻烦的函数写法 |
Union类型
之所以单独拿出来说,是因为Union Type的设计几乎是Elm的精髓。首先,它类似于枚举(enum)的概念,通过type enum = A | B | C的形式定义一个类型。这是简单的Union Type的使用。
Union Type还有Tagged Union的用法。即下面这样。这意味着User可以是不带信息的Anonymous或带有String信息的Named。Anonymous和Named是User的两个构造函数。其中Named接受一个String类型入参构造User类型。
1 | type User = Anonymous | Named String |
1 | type User = Named | Named String -- Wrong! |
结合上面的特点,可以很容易地将相似数据结构或设计抽象为单一模板,如举例中的将时间轴、日志等统一抽象为widget。思路:逐个击破,合而为一
由于Union Type可以递归定义,通过Union Type甚至可以构建链表和二叉树。
1 | type List a = Empty | Node a (List a) |
此外,Elm中的错误处理Maybe和Result也是基于Union Type实现的。
因为Union Type的不同子类型可以有自己独特的构造函数,且支持解构赋值,因此非常适合用作实现状态管理的事件。Web App中的update函数接受的Html Msg类型实际上也是Union Type实现的。
函数
除了不能手动更改状态的变量(因此递归完全替代了循环结构),函数是Elm中最常见的存在。命令式编程中,函数用作告诉电脑该怎么做。函数式编程中,函数用作描述一种映射关系,告诉电脑要什么。Elm中函数像下面这样声明:
1 | square n = |
入参在上,返回值在下。入参间通过空格隔开,由于Elm支持函数柯里化,所以在函数的类型声明中,也是通过->隔开每个入参以及返回值的。由于函数变成了纯粹的“通道”,函数体中声明临时变量的语法通过let ... in的形式实现。
Elm中也有匿名函数,像下面这样,由反斜线\开头:
1 | square = |
函数间通过|>和<|连接减少括号的使用。例如下面这样
1 | viewNames1 names = |
同时,可以通过>>和<<构造复合函数。``用来将第n个函数入参前置,使得居于更符合语法习惯,如buyMilk `then` drinkMilk中buyMilk参数被提前。n可以通过infixr设置。
其中可能较难理解的是递归完全替代了循环结构,Elm类似其他函数式语言,没有for和while。它用描述问题的方式,通过递归解决普通的循环问题,下面举两个例子:
1 | reverse : List a -> List a |
可以找到规律:
Usually you define an edge case and then you define a function that does something between some element and the function applied to the rest.
更具体的解释可以看参考链接3。
控制结构
Elm中没有for和while循环(都通过递归实现了)。但是存在if和case语句。
1 | if powerLevel > 9000 then "OVER 9000!!!" else "meh" |
杂项
++连接字符串,+表示相加- Elm不会进行强制类型转换
- 缩进会影响语句解析
- list中所有元素类型必须一致
- tuples设计类似python
- records类型不允许访问不存在的属性
//用来进行C风格的除法- Elm中!用于连接Model和Cmd,用
/=表示!=,同not表示!
Elm的语言设定大不同于C风格,所以,多写去熟悉它的语法风格吧。
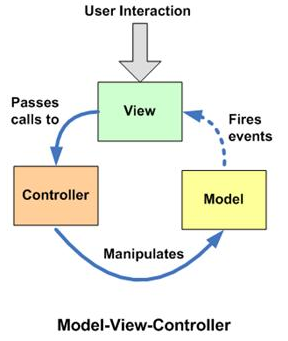
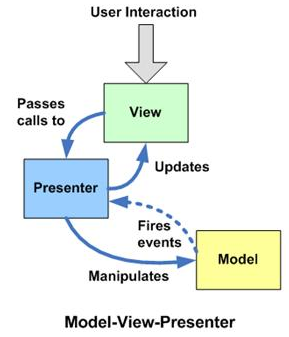
Elm架构
Elm构建Web App的架构为MVU(不考虑Cmd和Subscription的话),这和目前大部分MVVM框架一样,致力于减少UI维护,减少不必要的状态修改来更好地定位错误。有意思的是,Elm也采用了Virtual DOM的设计。
- Model,类似Web App的state,通常为
records类型 - Update,更新state的唯一方式(类似于action或commit),通常类型为
Msg -> Model -> (Model, Cmd Msg) - View,根据state渲染HTML的方式,通常类型为
Model -> Html Msg
Update部分,通常像下面这样,接受Union Type的Msg,并通过case ... of接受到附在Msg上的payload。
1 | update : Msg -> Model -> Model |
View部分,所有常用的标签名和属性名都被封装为函数,接受属性列表和子元素列表两个入参,像下面这样。
1 | view : Model -> Html Msg |
将M、V、U三部分结合在一起就可以构造简单的web应用了。当有异步任务等复杂情况出现时,需要通过Cmd和Subscription实现。
Effects

说这两位之前,我们要回顾下之前的工作流。仔细观察就能发现,我们所做的事只是描述了接受Html Msg后如何生产新的Model并根据新的Model生产新的Html Msg交给Elm Runtime,之后的脏活累活都交给Elm干了。根据Elm的描述,除了vDOM外,它还使用了下面两个手段提升效率:
- Skip Work,通过
lazy(类似React的shouldComponentUpdate)限制更新频率 - Align Work,通过
Html.keyed(类似React的key)减少无意义的diffing。
回到正题,Cmd和Subscription也是对Msg所做的外层包装而已。除了能向Elm Runtime pipe Html Msg外,当然也可以发送命令或订阅事件

。Html, Cmd, Sub三者实际上没太大区别,都是我们将生成的数据交给Elm Runtime,剩下的做甩手掌柜。它可以帮助我们:
- 更好的debug
- 确保Elm函数的线性时不变
- 优化HTTP连接,缓存effects
下面是一个Sub的例子:
1 | -- SUBSCRIPTIONS |
错误处理
之前提到过Elm致力于“编辑时无bug=>Runtime无bug”。除了强类型和无状态(实际上是Immutable的状态)外,还有Maybe和Result的辅助。
Elm treats errors as data.
参考null的糟糕设计,Elm通过
1 | type Maybe a = Nothing | Just a |
定义了Maybe类型。结合case of的特殊情况处理,通过option types的方法替代Null。core/Maybe模块还有withDefault,andThen等其他方法。
类似于Maybe,Result用Union Type的形式定义了不可靠操作的返回值。
1 | type Result error value = Err error | Ok value |
通过Err和Ok两种类型,隐含了其他语言中的try catch操作,避免exception的出现。Elm库函数是实现了Result类型的,如Http.get。Result预定义在core/Result中
Task
另外,Elm中有Task用来处理异步操作中的失败情况。类似于JS中的Promise。使用思路是先通过succeed方法和fail方法定义Task再使用。
1 | type alias Task err ok = |
在Elm由0.17升级到0.18时,有两种方式执行一个Task。Task.perform和Task.attempt。前者针对从不返回错误的task,后者针对可能出错的task。更重要的是,在Task.attempt中结合了熟悉的Result模型。
1 | perform : (a -> msg) -> Task Never a -> Cmd msg |
互操作性
Elm的互操作性体现在和JSON以及JavaScript上。
与JSON
通过Json.Decode和Json.Encode完成相关工作。解析部分由decodeString完成。
1 | decodeString : Decoder a -> String -> Result String a |
由第一个参数指定decoder类型,如 decodeString int "42"就指定了一个整数的解析器。在多数情况下,JSON字符串并没这么简单。这时,需要先利用基本的int、string、list、dict解析器结合map2、map3等构造相应的Decoder,再交给decodeString处理。函数返回Result类型。
1 | import Json.Decode exposing (..) |
是不是很麻烦。不像JavaScript里一个JSON.parse()完事,确实Elm解析JSON的笨拙为人诟病,官方的pipeline包通过|>组合Decoder,让语法稍微好了一点。最新的0.18版本下有json-extra提供更方便的decoder选择。
1 | import Json.Decode.Pipeline exposing (decode, required) |
可这距离JSON.parse还是不够啊。于是有人写了个根据Records类型生成decoder的工具,或者在线生成。
相比之下,encode过程就简单多了。
与JavaScript
有两种方式,port或flag。
前者类似于在Elm应用上凿洞,用类似订阅发布的模式工作。需要在文件开头的module声明前,额外加上port关键词,同时需要暴露的接口前也需要port关键词。
1 | port module Spelling exposing (..) |
1 | var app = Elm.Spelling.fullscreen(); |
后者暴露program的init给外部JavaScript。在声明Elm program时,使用programWithFlags而非program。
1 | init : Flags -> ( Model, Cmd Msg ) |
1 | var app = Elm.MyApp.fullscreen({ |
Elm的思路是不向后兼容,避免过去问题的引入。只通过port和flags的方式,借由Elm runtime和外部JS沟通,避免自身的runtime exception,把问题只留在JavaScript部分。
工程实践
使用Elm编写简单的应用时,可能一个.elm文件完成后,就可以直接elm-make index.elm --output index.js就OK了。当工程较大时(目前还没怎么看到生产环境用Elm的),必然需要拆分组件。
Elm在设计上,拆分的比MVVM框架更细。它拆分到了函数的级别,由于它pure function的特点,不受状态的束缚,重用函数比MVVM框架顾虑少太多了。如,重用view函数就相当于React和Vue中的函数式组件。重用update函数,可以实现MVVM中“组件A改变组件B,组件B改变组件C,组件C改变组件A”的史诗级难题。
封装和应用是通过module ... exposing ...和import ... exposing ...的语法完成的。Elm会去elm-package.json中的source-directories以及dependencies中声明的路径和包下寻找import对应的东西。剩下的,只要控制好复用程度,在习惯Elm语法后,就可以轻松且高逼格地编写Web应用了。
Elm编写好,且通过elm-make成功编译后,会得到一个.js文件,在需要的HTML文件中引入,会得到一个Elm全局对象,存储了所有的program。每个program都有embed方法和fullscreen方法绑定在HTML文件中。之后,大功告成!
参考作者所写的TODOMVC是个不错的开始。
FAQ
Q:Where are my components? And how do they communicate?
A:参见Scaling The Elm Architecture
Q:What’s the “Elm style”?
A:回头看看前言一节最后放的两个Elm开发感受,Elm中,View和Updates两部分均可以拆解成多个/组helper functions。最后在一个门面文件中汇总。Elm将state、updates、view放在一个文件,对开发更友好。Elm的优势在于函数式编程特点的帮助(无副作用/纯函数/强类型/出色的错误处理机制)和对人机交互模式的优异抽象。它的问题在
- 不完善的文档
- 蹩脚的互操作(interop)设计(port和flag)
- 学习曲线陡峭
- 缺乏成熟的成套解决方案
- 坑爹的JSON支持
Q:Who will save my front-end routing?
A:有的,借助Elm Navigation package就可以做到,具体如何和状态变化绑定起来参见tutorial的routing部分