Javascript事件并发与Event Loop浅析
引子
首先我们先来看下面一段代码。
1 | (function(){ |
尽管结构复杂,但是只要对JavaScript的异步和回调有点了解,就能知道它的输出结果是’1 2 3 4 “result” 5 6 7 8’。
并发模型
JavaScript中的异步和回调是语言本身的一种特色。包括上文中的setTimeout函数,Promise对象以及node.js的fs.readFile等。将耗时的操作非阻塞地完成,可以大大提高程序的执行效率。而这些都和JavaScript的并发模型密切相关。与C++, Java多线程处理方式不同,JavaScript中的并发是基于事件循环(Event Loop)的。
Event loop is a programming construct that waits for and dispatches events or messages in a program.
执行图
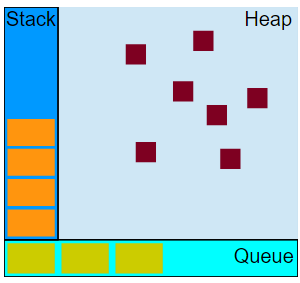
Stack
函数调用时所用的执行环境栈。当函数被调用时,会进入一个执行环境(execution context)。当在函数内部调用其他函数(或自身调用)时,会进入新的执行环境,并在函数返回时回到原来的执行环境,并将原先的执行环境销毁。根据ECMA定义的概念,代码在执行环境中,还会创建变量对象的作用域链,以确保当前执行环境的有序性。最外层执行环境是全局环境(如window)。具体作用域链和执行环境的介绍,将放在其他文章中进行。
函数执行过程中的执行环境栈即Stack。如下面的代码中,调用g时,形成第一个堆栈帧,包括参数21和局部变量m等。g调用f后,会创建第二个堆栈帧,置于其上,包含f的参数84和局部变量12等。f返回后,第二层栈帧出栈,g返回后,栈就空了。
1 | function f(b){ |
Heap
存放JS中引用类型的堆,JS的引用类型通过类似于图的形式存储,方便进行垃圾回收。具体介绍可以参考红宝书,这里从略。
Queue
JavaScript运行时的待处理消息队列,其中的每个消息都与对应的回调函数绑定(未绑定的消息不会进入队列)。当栈空时,会从栈中取出消息进行处理,这个过程包括调用回调函数,形成调用栈等。当栈在此为空时,代表这个消息处理完成。
首先我们要明确一点,JavaScript的并发是单线程的。在程序中(如浏览器)运行时,JS引擎跑着两个线程。一个负责运行本身的程序,叫做主线程。另一个负责主线程与其他线程的的通信,即Event Loop。当遇到异步的任务时,主线程将交由其他线程处理,并根据情况将对应的消息入队到信息队列(Message Queue)等待处理,如果消息未绑定回调函数,则不入队。
当调用栈清空后,队首消息依次出队,并调用绑定的回调函数,产生函数执行环境和调用栈等。直到消息队列清空为止。以上就是JavaScript中的事件循环。
不同的web worker或跨域的iframe都有各自的栈、堆以及消息队列。不同的环境通过postMessage方法进行通信(需要双方监听message事件)。
setTimeout和setInterval
在明白什么是时间循环后,setTimeout和setInterval这两个定时器函数就比较容易理解了。由于JavaScript运行在单线程的环境里,setTimeout和setInterval的定时时机实际上并不能得到保障。
定时器对队列的工作方式是,在在当前时间过去特定的时间后将代码插入,这并不意味着之后会立即执行,而只能保证尽早执行。。如下面的代码中,设定的250ms延时并不代表在onclick事件触发后的250ms立即执行。实际上,如果onclick的事件处理程序执行超过了250ms,定时器的设置将不再有意义(因为匿名函数的执行时机由onclick事件处理程序何时结束决定)。由此可见,setTimeout的时间间隔往往会比设计时长。
1 | var btn = document.getElementById("my-btn"); |
setInterval道理类似,和setTimeout不同的是,setInterval函数会将回调函数定时地插入消息队列的末端。为了避免定时器代码在执行完成前就有新的相同代码插入,造成严重性能问题,聪明的JavaScript引擎仅在队列中没有其他定时器实例时才会插入新的定时器代码。
但是这么做却也带来了一个问题,那就是
- 某些间隔会被跳过
- 多个定时器间的间隔会比预期的要小。
后者可以通过循环调用setTimeout来避免。
另外,微软在IE 10中实现了setImmediate方法,来实现真正的回调函数“立即执行”,而在实际运行中似乎和setTimeout的时间类似。
Macrotask 和 Microtask
首先我们还是先来看一段代码:
1 | setImmediate(function(){ |
它的结果是什么呢。这里我们就要知道setTimeout, setImmediate, Promise.then, process.nextTick这些异步操作的优先级了。回答这个问题之前,我们先了解一下Macrotask和Microtask两个概念。
Macrotask又叫task,是消息队列中一个个的message,一次event loop里面可能会有多个task,task有自己的task source,比如说setTimeout来自于timer task source,又或者和用户交互相关的来自user interaction task source。
Microtask和Macrotask类似,区别在于它更轻量级,并非每次都在task末尾才执行,只要函数栈为空掉,Microtask就会执行。由此可见它的优先级要更高些。
总结一下,它们的特点如下:
- 一个事件循环(event loop)会有一个或多个任务队列(task queue) task queue 就是 macrotask queue
- 每一个 event loop 都有一个 microtask queue
- task queue == macrotask queue != microtask queue
- 一个任务 task 可以放入 macrotask queue 也可以放入 microtask queue 中
- 当一个 task 被放入队列 queue(macro或micro) 那这个 task 就可以被立即执行了
简单点总结事件循环就是
- 在 macrotask 队列中执行最早的那个 task ,执行浏览器渲染,然后移出
- 执行 microtask 队列中所有可用的任务,然后移出
- 下一个循环,执行下一个 macrotask 中的任务 (再跳到第2步,直到没有task和microtask)
在实现上,macrotask主要有setTimeout setInterval setImmediate I/O UI渲染;microtask主要有Promise process.nextTick Object.observe MutationObserver。由于microtask会耽误task的执行,尤其是在较多时甚至无法执行消息队列中的task,包括UI刷新。因此process.nextTick默认上限为1000,避免上述情况的出现。当调用次数过多时,会抛出栈溢出错误。
所以,上面的执行结果将是3 4 6 8 7 5 2 1


