前言
此文源于6月初的一个知乎问题“为什么市场上优秀的前端这么少,国外也是这样吗?”,简单阅览了答案后才发现,有那么多的web技术自己还闻所未闻。于是开始从javascript(js)开始,广度优先地学习起一些新技术(当然有些列举的已经不算新了)。在学习的过程中,也发现了作为一名前端工程师的不易:
- 科技树太广,需要广泛的知识面
- 随着js的发展,前端技术已渗透到各个方面,做前端≈做全栈
- 新技术出现太快,需要保持open mind
这里整理了对一些技术的学习笔记,几乎都是与js相关的技术,按照分类列举在下面(有些未做学习):
- 框架:AngularJS, EmbedJS, ReactJS, ExpressJS, Backbone.JS
- 环境:NodeJS
- 包管理:Bower, npm
- 包构建:Browserify, Webpack
- 任务自动化:Grunt, Gulp
- 模块化规范:RequireJS, CommonJS, AMD, CMD
- DOM操作:jQuery, Zepto
- 数据库:MongoDB
- 可视化:D3
- 测试工具:Protractor, Selenium, PhantomJS, mocha
- 其他:Jade, Markdown, Socket.io等
关于本文,还有一些想说的。首先,前端技术发展很快,文中提到的用法等内容是有一定时效性的,请谨慎;其次,写本文的时候是奔着信息充分,便于日后检索去的,所以当作工具书更为适合;最后,水平有限,纰漏还望指正。
NodeJS
What and Why
NodeJS是以下介绍的许多技术的出发点和基础。它让JS从前端技术走到后台开发。对于独立运行的JS来说,NodeJS就是一个解析器,就像PHP。但是和PHP不同的是,NodeJS在实现应用的同时,还实现了整个HTTP服务器,不像PHP需要Apache等的帮助。
NodeJS具有很好的事件机制和异步IO模型。类似于浏览器,NodeJS提供了内置对象给用户操作。
安装
Windows下和Mac OS X系统下,分别去nodejs.org下载.msi和.pkg后缀的安装文件。Linux下需要下载.tar.gz包编译安装。
Windows环境下安装后可以在命令行中使用node –v, npm –v查看是否成功。另外终端下直接输入node命令可进入命令交互模式.
模块
运行简单的web应用程序时,可以直接通过命令或是node example.js的形式启动。在程序稍大时,通常会将代码模块化。文件即模块,通过require、exports、module命令导入、导出、声明模块。范例:
var foo = require("./foo");
exports.hello = function(){
console.log("Hello World!");
}
module.exports = function(){
console.log("Hello World!");
} require函数用于在当前模块中加载和使用别的模块,返回一个模块导出对象。模块名可以以相对或是绝对路径。模块后缀名可省略。exports对象用于导出模块共有方法和属性,导出的内容由别的模块使用require获取。module对象可以访问当前模块的一些相关信息,包括导出对象。
一个模块中的JS代码仅在模块第一次被使用时执行一次,并在执行过程中初始化模块的导出对象。之后,缓存起来的导出对象被重复利用。通过命令行传递给NodeJS启动的模块称为主模块。
最后,NodeJS支持使用C/C++编写二进制模块,使用方法和JS模块相同,它可以使用操作系统提供的所有功能,潜能很大,但是难以跨平台。这里从略。
代码组织
require函数支持绝对、相对路径,可以通过node_modules目录,NODE_PATH定制。
当模块较复杂时,可以使用包结构将多个子模块。将这些子模块放在同一目录下,使用index.js作为入口模块。这样路径只需写到文件夹即可。范例:
var head = require('./head');
var body = require('./body');
exports.create = function (name) {
return {
name: name,
head: head.create(),
body: body.create()
};
}; 另外,使用package.json可以自定义入口模块的文件名和存放位置。使用name,main即可
标准的工程目录应该包括bin/, doc/, lib/, node_modules/, tests/, package.json, README.md等部分,分别存放命令相关代码、文档、API相关代码、第三方包、测试用例、元数据文件、说明文件。nodeJS有许多内置的模块可供使用,下面分几个部分分别介绍之。
文件操作
NodeJS作为后台解析环境,可以完成很多文件操作。使用NodeJS内置的fs模块的API可以完成如拷贝等功能。拷贝小文件时,使用writeFileSync, readFileSync即可完成,大文件拷贝时,使用createReadStream, pipe, createWriteStream可以完成。
同时NodeJS还提供了Buffer,Stream,Path用于完成更完善的文件操作功能。
Buffer对象是与String对等的二进制数据类型,可以用to_string和string相互转换。不同的是,buffer对象是可写的,这点和C很像。因此,buffer更像是指针操作的C语言数组,如使用slice命令更像是将指针赋予了新值,对新值做的修改对原值有直接影响。因此,拷贝buffer时,需要先创建一个新的buffer才能复制新数据。
Stream对象在内存无法一次装下大文件的数据时,或需要一边读取一边处理时提供对数据流的操作,例如可用createReadStream创建一个只读数据流rs,rs有on, pause, resume, end等功能。Stream对象都是事件驱动的,上文提到的rs即可监听data, end, drain等事件。pipe方法提供了防爆仓控制,用于大文件拷贝。
fs模块提供了许多有用的API,包括文件属性读写,文件内容读写,底层文件操作。这些API大多为异步,不过都有同步版本,并在函数名后添加Sync。
Path模块用于文件路径的操作。Normalize方法将传入的路径转换为标准路径,join方法将传入的多个路径拼接成标准路径。
下面是一个遍历目录的同步例子,用到了以上介绍的内容:
function travel(dir, callback) {
fs.readdirSync(dir).forEach(function (file) {
var pathname = path.join(dir, file);
if (fs.statSync(pathname).isDirectory()) {
travel(pathname, callback);
} else {
callback(pathname);
}
});
} 除了以上介绍的文件操作外,一些其他需求也经常出现,如去文件BOM头,GBK转换UTF-8编码,单字节编码。
NodeJS提供的这些文件操作功能对于变现前端工具是很有帮助的。
网络操作
由于NodeJS的用途是实现高性能的Web服务器,给独立运行的JS提供解释环境,它所提供的网络操作可以完成相对底层的网络操作,如Socket和HTTP协议相关。NodeJS提供了http, https, url, querystring, zlib, net等库帮助开发者实现网络编程。
http模块提供了两种使用方式: 作为服务端使用和作为客户端使用。如测试第1例中所写,createServer方法创建一个服务器(这也是最常用的一种用法),然后抵用listen方法监听端口。客户端每请求一次,创建时输入的回调函数就调用一次。函数中的request和response实际上也是数据流的格式,所以可以用文件操作函数来读取,如request.on, request.write等方法.
在作为客户端使用时,有get, post等方法,同样地,可以使用response对象访问响应头数据,还能把response对象当作一个只读数据流访问响应体数据。用法范例如下:
http.get('http://www.example.com/', function (response) {
var body = [];
console.log(response.statusCode);
console.log(response.headers);
response.on('data', function (chunk) {
body.push(chunk);
});
response.on('end', function () {
body = Buffer.concat(body);
console.log(body.toString());
});
}); https模块和http模块很类似,区别在于https模块需要额外的SSL证书处理,在createServer时,将公钥和私钥放在option里作为输入参数。同时https的addContext方法还可以使用多个域名提供服务。在客户端模式下,https模块默认拒绝连接未从颁发机构购买SSL证书的服务器。在options中添加rejectUnauthorized: false即可在开发条件下允许自制证书。
url模块允许生成、解析、拼接url。url分为protocol, auth, hostname, port, pathname, search(query) hash/host, path, href等部分。parse方法可以将url解析成以上部分,且不要求url完整。parse的第二和第三个参数分别可以将query部分转换成对象和解析不带协议头的URL。相反地,format方法允许将URL对象转换为URL字符串。resolve方法支持URL的拼接。
querystring实现了query字符串和参数对象之间的转换,类似于PHP的$_GET,$_POST。同样适用parse方法和stringify方法完成两个方向的转换。
zlib函数支持压缩和解压到功能,在对HTTP响应体数据压缩时,可能需要用到这个模块。下面的范例是官网文档使用的判断用户端是否支持gzip,并在支持时返回gzip之后的响应体数据:
http.createServer(function (request, response) {
var i = 1024,
data = '';
while (i--) {
data += '.';
}
if ((request.headers['accept-encoding'] || '').indexOf('gzip') !== -1) {
zlib.gzip(data, function (err, data) {
response.writeHead(200, {
'Content-Type': 'text/plain',
'Content-Encoding': 'gzip'
});
response.end(data);
});
} else {
response.writeHead(200, {
'Content-Type': 'text/plain'
});
response.end(data);
}
}).listen(80);同理,zlib可以使用gunzip解压缩文件。
net模块可以创建底层的socket服务器或是客户端,但是在前端领域使用范围并不广。它可以在socket层面实现HTTP请求和响应。需要有网络编程的底层认识和HTTP协议的熟悉。
最后还需要注意的几点是,http模块创建的服务器返回响应时默认使用chunked传输模式,因为writeHead方法后的响应体数据长度未知,设置header中的Content-Length字段后,NodeJS就不会自动添加Transfer-Encoding字段。http模块提供一个全局客户端http.globalAgent,允许直接使用request方法和get方法,但是最多只允许5个并发连接,通过http.globalAgent.maxSockets可以修改这个值。
进程管理
NodeJS可以可以感知和控制自身进程的运行环境和状态,也可以创建子进程并与其协同工作,这使得NodeJS可以把多个程序组合在一起共同完成某项工作,并在其中充当胶水和调度器的作用。与之相关的API有process, child_process, cluster等等。
其中process对象可以感知和控制NodeJS自身进程的方方面面,它是一个全局对象,可以在任何地方使用。通过process可以感知nodeJS进程的各种状态,如process.argv获取命令行参数。它也继承eventEmitter。有exit等事件可以监听,同时有exit, stdin, stdout, env等对程序的精细控制。
child_process可以创建和控制子进程,利用spawn, fork方法创建新的进程,使用exec, execFile方法执行命令、文件。Spawn方法还被其他API做进一步的封装,以适应不同场景。cluster模块是对child_process的进一步封装,用于解决单进程NodeJS Web服务器不能充分利用多核CPU的问题。
这里以进程降权和子进程间通过信号通讯为例,熟悉简单API的一些使用:
http.createServer(callback).listen(80, function () {
var env = process.env,
uid = parseInt(env['SUDO_UID'] || process.getuid(), 10),
gid = parseInt(env['SUDO_GID'] || process.getgid(), 10);
process.setgid(gid);
process.setuid(uid);
});
/* parent.js */
var child = child_process.spawn('node', [ 'child.js' ]);
child.kill('SIGTERM');
/* child.js */
process.on('SIGTERM', function () {
cleanUp();
process.exit(0);
}); 实际上父子进程都为NodeJS进程时,可以通过IPC通讯双向传递数据,双方通过on和send方法在IPC上双向传递数据。具体范例见官网对child.send()的范例。这种情况下,子进程通常使用process.fork方法创建。
特点
正如What and Why中所说,NodeJS最大的特点就是事件机制和异步调用。JS是单线程运行的,但是setTimeout,setInterval这样的函数可以通过创建平行进程的形式实现异步的效果。因此实际运行时,JS主进程会顺序向下执行除回调函数以外的代码,这也意味着,回调函数的执行在JS主线程后。例子见参考。
因此,虽然NodeJS提供了很多异步函数的同步版本,但是为了利用它的优势,熟悉回调和异步的编码思路还是很必要的。如,在同步中以返回值的形式嵌套调用,异步里采用回调函数套回调函数。在遍历等步骤时要更为复杂。
异常处理也是如此,由于异步调用的形式会打断错误冒泡的路径,使之不会被try语句catch住,因此NodeJS提供的try catch语句只能在同步形式下使用。异步API通常采用向回调函数中传入err参数实现。从以上可以看到,NodeJS最大的特点会增大代码的复杂度,尤其在有异常处理的情况下。对此,NodeJS提供了一些解决方法。
domain模块可以简化异步代码的异常处理。对于全局异常,可以直接通过process的uncaughtException事件捕获。对于普通异常,我们为每个请求创建一个子域,子域内运行的代码可以随意抛出异常,这些异常可以通过子域对象统一捕获,会使得代码简介很多。范例如下:
function async(request, callback) {
// Do something.
asyncA(request, function (data) {
// Do something
asyncB(request, function (data) {
// Do something
asyncC(request, function (data) {
// Do something
callback(data);
});
});
});
}
http.createServer(function (request, response) {
var d = domain.create();
d.on('error', function () {
response.writeHead(500);
response.end();
});
d.run(function () {
async(request, function (data) {
response.writeHead(200);
response.end(data);
});
});
}); 根据NodeJS官方文档的说法,无论怎么捕获到异常,都强烈建议处理完异常后立即重启程序,而不是让程序继续运行。这是由于NodeJS的部分API内部是用C/C++实现的,代码在执行过程中穿梭在JS引擎内部和外部,因此JS的异常抛出机制可能会打断正常的代码执行,导致C/C++部分代码表现异常。而使用JS语句捕获异常时一般捕获到的都是JS本身的异常,不用担心上述问题。
使用示例
这一部分主要展示了一个完整的应用实例。
1. 为了展示NodeJS的最基本的使用和简单的调试方式。我们创建一个用于启动应用的主文件,起名为server.js,写入如下代码。
var http = require("http");
http.createServer(function(request, response){
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello, World!");
response.end();
}).listen(8888);将文件放在NodeJS目录下(其他目录亦可),接着用NodeJS执行这段脚本。打开浏览器访问http://localhost:8888,可看到此网页。对比PHP还是看出很大不同的。
回调函数很好地反映了使用JS做服务器的特点:事件驱动、异步。在请求到达后交给onRequest()函数处理,函数接受两个参数request和response。
2. 上文的server.js是启动服务器基本代码,需要交给主文件index.js使用。因此,采用模块一节介绍的方法,使用exports对象。新建index.js,使用require导入。
var http = require("http");
function start(){
http.createServer(function(request, response){
console.log("Request Received");
response.writeHead(200, {"Content-Type": "text/plain"});
response.write("Hello, World!");
response.end();
}).listen(8888);
console.log("Server has started.");
}
exports.start = start;
var server = require("./server");
server.start();这次同样使用node index.js启动脚本,可以实现同样的效果。
3. 路由也是一个Web应用开发的关键一块。利用url模块可以完成这一功能。同时在server.js中,将route作为参数传入start函数中。在index.js中,导入router模块。router.js代码如下。
function route(handler, pathname){
console.log("Handle a request to " + pathname);
if(typeof(handler[pathname]) === "function")
handler[pathname]();
else
console.log("Handler for "+ pathname+ " not found.");
}
exports.route = route;4. 在start路径下允许用户输入数据,并在upload目录下获得POST数据,需要用到stream和querystring的内容。Server.js和requestHandler.js关键部分定义如下:
function start(router, handler){
http.createServer(function(request, response){
var pathname = url.parse(request.url).pathname;
var postData = "";
console.log("Request for "+pathname+" received");
request.setEncoding("utf-8");
request.on("data", function(chunk){
postData += chunk;
console.log("Receive POST data chunk "+chunk+".");
});
request.on("end", function(){
router(handler,pathname,response,postData);
});
}).listen(8888);
console.log("Server has started.");
}
var querystring = require("querystring")
/* requestHandler.js */
function start(response, data){
console.log('Handler \'start\' was called.');
var body = '<html>'+
'<head>'+
'<meta http-equiv="Content-Type" content="text/html; '+
'charset=UTF-8" />'+
'</head>'+
'<body>'+
'<form action="/upload" method="post">'+
'<textarea name="text" rows="20" cols="60">'+
'<textarea>'+
'<input type="submit" value="Submit text" />'+
'</form>'+
'</body>'+
'</html>';
response.writeHead(200, {"Content-Type": "text/html"});
response.write(body);
response.end();
}
function upload(response, data){
console.log('Handler \'upload\' was called.');
response.writeHead(200, {"Content-Type": "text/html"});
response.write("You have sent "+ querystring.parse(data).text);
response.end();
}
5. 利用NodeJS的异步特点和子进程模块,可以将start和upload函数中的耗时操作设为异步进行,将异步运行的结果交给回调函数处理。在requestHandler.js中添加exec语句即可。同时,允许用户上传文件,并将图片在浏览器中显示出来。可以用第三方插件完成大部分功能。这里从略。可以见更多中的Node入门。
更多
npm
简介
npm是NodeJS随同安装的包管理工具。由于NodeJS使用模块组织工程的特点,npm能解决NodeJS部署上的很多问题。它允许用户从npm服务器下载别人编写的三方包到本地使用、允许用户从npm服务器下载并安装别人编写的命令行程序到本地使用、允许用户将自己编写的包或命令行程序上传到npm服务器供别人使用。
同时,NPM还是NodeJS的开放式模块登记和管理系统。它构建了一个NodeJS模块平台,发挥了类似github的功能。
安装
npm一般随NodeJS一起安装。安装后,可以通过npm intall npm@latest –g进行更新。npm help和npm –l可以查看npm的帮助信息。
常用命令
npm init: 在项目文件根目录下,需要有package.json来完成模块的开发说明。该命令可以初始化新的package.json文件,通过询问的方式完成。使用参数-f和-y可以跳过询问。
npm set: 用来设置npm的环境变量,类似于git config –global。有init-author-name init-author-email init-author-urllicense等选项可供选择。针对某个项目有特殊设置时,可以另行npm config。
npm info: 查看模块具体信息。类似于查看package.json。还可以查看字段信息。如,npm info {{module_name}} description。
npm search: 按照模块名搜索具体模块。npm的包名必须唯一。
npm list: 树形结构列出当前项目安装的模块和其依赖模块。可以跟-global
npm install: 最常用的一个命令。安装可以选择本地(当前文件夹的node_modules下)或全局。全局安装只适用于工具模块。该命令甚至支持通过github代码库地址安装。参数-f可以强制重新安装一个模块。删除node_modules目录,执行该命令可以强制安装所有模块。
在模块后,可以用@后接版本号安装特定版本,latest表示最新版,beta表示测试版。后接--save会添加dependencies到package.json中。--save-exact可以添加确切版本。--save-dev添加到devDependencies中。可以简化为-S或-D。--production会安装dependencies中的依赖而不考虑devDependencies。
npm update: 升级已安装的本地或者全局模块。--depth可以指定迭代的深度,升级依赖的依赖。
npm uninstall: 卸载已安装模块。
bpm run: 执行package.json中的scripts字段对应的脚本。其中npm run test和npm run start可以简写成npm test和npm start。可以将脚本存成文件,在scripts字段中写上文件路径。同时,npm run执行的命令可以跟命令行参数。(实际上,grunt和gulp这样的工具就是完成此类工作)
npm run的每个命令都有两个钩子pre和post。在执行命令command之前,npm会检查是否有precommand,执行之后会检查是否有postcommand。同时npm run可以使用一些内部变量,如package.json中的name字段可以用$npm_package_name代表。config字段里可以设置内部字段。
npm link: 将开发中的模块链接中本地的node_modules中,方便边开发边使用。npm unlink可以删除符号链接。
npm bin: 执行本地node_modules/.bin目录下的命令。
npm adduser: 在npmjs.com中添加一个用户。
npm publish: 发布模块,在拥有npm账户后。使用npm login登录,接着在本地目录下输入命令即可发布模块。--tag可以为发布模块添加标记
npm deprecate: 废弃某个版本或某个版本范围的模块,后面可以跟警告文本。如npm deprecate mymodule@"<0.2" "fix critical bugs"
npm owner: 管理模块的维护者。有ls, add, rm命令可以选择。
其他的命令还有npm install . –g可用于发布包前的本地测试;npm update cache clear可以清空缓存;npm unpublish {{package}}@{{version}}可以撤销自己发布过的某个版本代码等。更多详细介绍见官网文档
下载第三方包
使用命令npm install {{module_name}},将包下载到node_modules后,直接使用require({{module_name}})即可加载第三方模块。同时,修改package.json,添加dependencies项,即可批量加载第三方包,这样做的好处在他人加载你的模块时是非常明显的。用户只需关心自己直接使用的第三方包,而不需要自己解决依赖问题。
安装命令行程序
方法和上面类似,如npm install pug –g(-g表示全局安装),全局安装时,pug默认会安装到/usr/local(for Linux)或 %APPDATA%\npm(for Windows)下。npm会自动创建Linux下的软链和Windows下的.cmd文件。
发布自己的包
需要在npm注册自己的账号,之后运行npm adduser。账号配置完成后,编辑package.json文件,包括name, version, dependencies, main, bin, man等内容,之后就可以在package.json目录下运行npm publish发布代码了。package.json下字段的更多解释参见官网文档。下面是一个package.json的样例
{
"name": "my_package",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "ag_dubs",
"license": "ISC",
"repository": {
"type": "git",
"url": "https://github.com/ashleygwilliams/my_package.git"
},
"bugs": {
"url": "https://github.com/ashleygwilliams/my_package/issues"
},
"homepage": "https://github.com/ashleygwilliams/my_package"
}版本号控制
npm使用语义版本号进行版本号控制。分X.Y.Z三位,分别代表主版本号,副版本号,补丁版本号。其中主版本号对下不兼容,有大变动,次版本号只是新增功能向下兼容,补丁版本号只是修复bug。
在这个保证下,dependencies可以指定一定范围的版本码。包括>, >=, <, <=, ~, 0.0.x, *, -等等。
小结
npm是NodeJS自带的包管理工具。在复杂的工程背景下,通常需要使用许多的第三方包,在第三方框架下搭出可靠好用的应用。尤其在新技术层出不穷的web应用中,包管理成了很重要的一个环节。对于使用模块构建工程的NodeJS,NPM这样的包管理工具将更有利于它的发展和开发者的使用。
更多
Bower
简介
Bower由twitter推出,是一个和npm功能十分类似的包依赖管理软件。不同的是,npm管理整个工程项目的包依赖,而Bower专注于前端各网络资源的管理。它可以帮助快速搭建起前端以来环境,并管理各组件的版本状态。
和npm类似,Bower使用bower.json作为项目配置文件中。使用bower install命令时,后面可以跟包名、github路径、git仓库路径、url或者干脆不要参数。Bower本身的配置文件为项目根目录下的.bowerrc,通过directory, json, endpoint, searchpoint, shorthand_resolver指定了存放库文件的目录、描述库的json文件名,搜索库文件的路径,备选路径,库名称简写形式。下面是一个bower.json的样例:
{
"name": "app-name",
"version": "0.0.1",
"dependencies": {
"sass-bootstrap": "~3.0.0",
"modernizr": "~2.6.2",
"jquery": "~1.10.2"
},
"private": true
} 使用
通过npm intall bower –g全局安装bower,以便可以使用bower命令。通过bower help可以查看所有的bower命令。bower命令和npm命令是很类似的。有init, install, cache, search, list, info, uninstall等命令。Bower在下载依赖包时,会保存一份到缓存中,通过bower cache list查看。
Bower or npm?
由于前后端资源特点的不同,npm基于CommonJS的规范开发,是利于后端模块的依赖管理的,通过package.json管理树形的依赖结构,模块间用require、export沟通。而这在带宽紧张的前端是不完全适合的,前端更需要扁平和松散的依赖关系,减少文件的传输次数。因此,使用简单的Bower在推出后,收到了很大欢迎。但是Bower的缺陷也很明显,bower管理松散、缺乏统一的构建机制。包的格式并没有限制,只通过bower.json沟通。同时,bower缺少npm那样的registry,而直接取用github。
在Browserify, Webpack这样的工具出现后,使用npm管理前端时,不会出现CommonJS的规范下加上其他规范模块的不伦不类感。未来前后端包依赖统一管理的趋势是必然的,在node良好的生态环境下,使用npm统一管理似乎是更受欢迎的。
更多的讨论间知乎话题。
Browserify
简介与使用
如在Bower中提到的,浏览器端的文件并没有CommonJS这样的构建规范。因此,在使用npm管理时显得不伦不类。Browserify是node的一个插件,允许使用require的句法书写浏览器端的文件。通过browserify命令将入口文件打包输出,即可建立一个统一的依赖环境,且可以在html中只使用一条script或link等引入。
假设我们项目需要backbone.js和jQuery两个模块。首先,通过npm install –g browserify全局安装它。之后新建main.js文件,将服务器端backbone模块转为客户端(即浏览器端)模块。先安装backbone和jquery模块,在main.js中写下如下内容:
// main.js
var Backbone = require('backbone');
var $ = Backbone.$ = require('jquery/dist/jquery')(window);
var AppView = Backbone.View.extend({
render: function(){
$('main').append('<h1>Browserify is a great tool.</h1>');
}
});
var appView = new AppView();
appView.render();
之后使用browserify将main.js转为app.js:browserify main.js –o app.js。就可以通过
<script src=app.js></script>管理与生成
使用browserify可以将CommonJS转为浏览器可以调用的格式(如上文),同时,它也可以对纯粹的前端模块打包,然后再html中通过一行命令完成调用。使用browserify-shim支持jQuery等的CDN加载。使用parcelify模块可以对插件自带的css文件进行打包。
Browserify指定-r参数,还可以在打包模块的同时,为浏览器提供require方法。Browserify还支持实时生成脚本文件,通过browserify的bundle方法写在js文件里。
更多内容请参考阮一峰的Javascript参考教程。
Webpack
类似于Browserify,Webpack也是前端资源管理和打包工具,不过适用范围更广。它可以将松散的有依赖关系的前端资源打包成单一文件,根据loader的不同,它可以将CommonJS, AMD, ES6, CSS, 图片, JSON等视作模块。
Why
现有的模块管理和打包工具(包括commonJS,CMD等)不能很好地对模块进行无缝整合生成适合浏览器端请求的的静态资源。在以下方面发挥不良:
- 拆分依赖树为按需加载的模块
- 减少初始化加载时间
- 将各种静态资源视为模块
- 自定义打包逻辑
- webpack支持同步和异步两种组织模块依赖的方法
- webpack只能处理原生js模块,但是loader转换器可以将其他资源转换成js模块
- webpack几乎可以处理所有第三方库,甚至运行使用动态表达式加载依赖
- webpack有丰富的插件和高速的运行效率
安装使用
通过npm全局安装npm install webpack –g或安装到项目依赖npm install webpack –save-dev。在全局安装下,我们可以通过webpack命令打包文件。根据官方样例,若有module.js和entry.js如下:
// module.js
module.exports = 'It works from module.js.'
// entry.js
document.write('It works.')
document.write(require('./module.js')) // add module
通过webpack entry.js bundle.js命令将文件打包,并在html文件中引入。在页面启动后,会先启动entry.js中的代码,其他的模块会在运行到require时再执行。
借助loader,webpack可以处理非javascript资源,从而通过require命令引入其他类型的模块或文件。loader本身是一个函数,它以管道的方式调用,将资源转换格式再传递给下一个loader,但是最后一个loader必须返回js。loader可以接受参数,且作为模块运行在nodejs环境中。因此我们可以通过npm来管理loader或在项目中自己写loader模块。
如导入css文件时,指定css-loader来读取它,再用style-loader将它插入到页面中,通过命令require("!style!css!./style.css")即可,或在webpack命令后使用参数--module-bind css=style!css。
配置文件
Webpack在执行时,除了命令行参数,默认会搜索当前目录下的webpack.config.js文件。这个问价有着类似于package.json的功能。也可以通过—config手动指定配置文件位置。例如,我们可以创建以下配置文件,替代上文的做法:
var webpack = require('webpack')
module.exports = {
entry: './entry.js',
output: {
path: __dirname,
filename: 'bundle.js'
},
module: {
loaders: [
{test: /\.css$/, loader: 'style!css'}
]
}
} 此外,借助插件可以完成更多loader之外的功能,在配置文件中指定plugins属性即可。实际上除了上面介绍的,配置选项还有很多(上面介绍的更常用),如watch, debug等等,参见官方文档对配置文件的讲解。
更多
在开发环境下,还有webpack-dev-server辅助浏览项目中的页面和资源输出,并可以在浏览器中的localhost:8080/webpack-dev-server/位置下查看进度。详情可以查看官网。
本节内容大多参考官网和Webpack中文指南。个人认为这种工具型的技术实操学习起来更快。
Grunt
入门
在JS开发的过程中,经常会遇到一些重复性工作,如压缩代码,检查语法错误,将Sass文件转成CSS文件等。Grunt就是便于我们自动管理和运行任务的自动任务运行器。它会按照预定顺序执行它们,简化重复性工作的负担。
使用grunt前,需要使用npm命令将grunt-cli全局安装。需要注意的是,grunt-cli是通过组织安排其他grunt组件起到组建作用的。使用grunt时,需要在工程目录下添加package.json和Gruntfile两份文件,它们分别用来便于将项目发布为npm模块和配置和定义任务并加载Grunt插件。通常,最好在package.json中间添加grunt插件的依赖。
Gruntfile
Gruntfile由wrapper函数、项目于任务配置、加载grunt插件和任务、自定义任务及部分构成。下面就是一个Gruntfile的文件案例,加载grunt-contrib-uglify压缩资源文件。
module.exports = function(grunt) {
// Project configuration.
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
uglify: {
options: {
banner: '/*! <%= pkg.name %> <%= grunt.template.today("yyyy-mm-dd") %> */\n'
},
build: {
src: 'src/<%= pkg.name %>.js',
dest: 'build/<%= pkg.name %>.min.js'
}
}
});
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.registerTask('default', ['uglify']);
}; Wrapper函数:上文中的module.export = function(grunt){}部分。每一个Gruntfile都遵循此格式,所写的grunt代码必须放在此函数的代码块内。- 项目和任务配置:通过
grunt.initConfig()将grunt任务所需要的配置对象写在输入参数里面。理论上,这个对象可以存储任意的数据。在上面的案例里,通过grunt.file.readJSON将package.json中的元数据引入到grunt config。并通过制定uglify的属性,配置uglify任务。 - 加载grunt插件与任务:通过
grunt.loadNpmTasks({{plugin_name}})使用已用npm安装的grunt插件。grunt –help将列出所有可用的任务。 - 自定义任务:即上文中的
grunt.registerTask(),指定grunt的默认任务,在grunt命令后没有任务时,默认执行uglify任务。实际上,还可以通过grunt.loadTasks加载定义好的外部任务。
任务配置
当运行一个任务时,grunt会自动查找配置对象中的同名属性。在同名属性下甚至可以定义不同的target针对不同任务环境,通过grunt {{task_name}}:target的形式访问。在普通环境下grunt会默认执行所有target。同时,在任务配置中,任务的options属性可以覆盖默认值,在不需要的时候可以忽略。
在文件操作中,grunt通过src-dest的形式定义文件映射,并提供了不同程度的描述和控制。在简洁格式下,通过为target至此那个src和dest属性完成src-dest映射。这种格式支持个每个映射指定额外属性。文件对象格式下,则是用目标文件名做属性名,源文件列表做它的值,这种方式可以指定多个映射,但是不能给每个映射指定附加属性。文件数组格式支持对应多个映射,且允许每个映射拥有额外属性。下面是它们的一些样例。
grunt.initConfig({
jshint: {
foo: {
src: ['src/aa.js', 'src/aaa.js']
},
},
concat: {
foo: {
files: {
'dest/a.js': ['src/aa.js', 'src/aaa.js'],
'dest/a1.js': ['src/aa1.js', 'src/aaa1.js'],
},
},
bar: {
files: [
{src: ['src/bb.js', 'src/bbb.js'], dest: 'dest/b/', nonull: true},
{src: ['tmp/**/*'], dest: 'dest/tmp/', filter: 'isFile'},
],
}
}
}); 上面concat的bar目标中,使用了filter过滤函数找到tmp目录下的所有文件还可以创建自己的过滤函数。Grunt支持在src中通过通配符指定源文件路径,关于通配符模式的语法,可以参见grunt中文文档。当源文件数目很多,难以一一列出时,可以通过dynamic_mappings动态指定文件映射关系。
使用<% %>分隔符指定的模板会从配置文件中读取响应数据来填充。因此,在其中写入grunt命令甚至也是可行的。之前案例里,也是通过grunt.file.readJSON读入外部文件导入配置的。
配置实例
假设我们的某个项目需要grunt-contrib-uglify, grunt-contrib-qunit, grunt-contrib-concat, grunt-contrib-jshint, grunt-contrib-watch这5个插件。首先,我们写好wrapper函数和初始化configuration对象。并通过
pkg: grunt.file.readJSON(package.json)Concat插件功能是将依赖的所有资源文件打包,通过指定options中的separator属性可以更改默认的合并输出文件间的分隔符,指定dist属性,确定将要合并的文件和合并后文件的存放位置。例如我们可以如下配置,将所有文件合并为与项目名同名的输出文件。
concat: {
dist: {
src: ['src/**/*.js'],
dest: 'dist/<%= pkg.name %>.js'
}
} Uglify插件用来压缩JS文件。我们可以指定options中的banner给出压缩文件的注释。可以简单地用文件对象的格式确定输入输出。这里我们将concat插件链接的这些文件压缩成一个.min.js文件。示例如下:
uglify: {
options: {
banner: '/*! <%= pkg.name %> <%= grunt.template.today("dd-mm-yyyy") %> */\n'
},
dist: {
files: {
'dist/<%= pkg.name %>.min.js': ['<%= concat.dist.dest %>']
}
}
} QUnit插件用来进行单元测试,只需为它指定用于测试的文件位置即可。示例如下:
qunit: {
file: ['test/**/*.html']
} JSHint插件可以检查代码中的潜在错误(即lint)。Files属性里是lint的对象。实例如下:
jshint: {
// define the files to lint
files: ['gruntfile.js', 'src/**/*.js', 'test/**/*.js'],
// configure JSHint (documented at http://www.jshint.com/docs/)
options: {
// more options here if you want to override JSHint defaults
globals: {
jQuery: true,
console: true,
module: true
}
}
} Watch插件用于检测指定文件的变化,在它们变化时执行指定的任务。只需指定files属性和tasks属性即可。
最后的最后,通过grunt.loadNpmTasks()将插件导入,并registerTask注册所需的任务,尤其是default任务(当然也可以注册其他可选任务)。
任务与插件
启动grunt时,默认附带要执行的任务,当不跟参数时,执行default任务。通过registerTask确定任务名和任务列表。如上面的一些例子。
使用grunt.registerMultiTask()还可以创建多任务,它通过输入的属性名和目标名执行任务,并在未指定目标时执行所有目标。在自定义任务时,可以通过grunt.task.run执行其他任务,还可以访问自身的参数如名称、输入参数做相应处理。通过grunt.task.require()检查依赖任务执行成功与否或配置属性是否存在。
在grunt 0.4的版本下,grunt-init被拆分成独立的模块,可以通过npm安装。通过grunt插件模板可以创建自己的grunt插件,用类似于npm的形式部署和发布。在发布时,注意命名空间。
Grunt cli是grunt的命令行工具。全局安装后,通过grunt –h即可查看grunt的所有命令。
更多
Grunt的中文文档介绍得很好,可用作入门。
Gulp
入门
Gulp是个grunt功能类似的自动化构建工具。它利用Node.js的流概念,在管道中传输数据流,从而完成项目构建。同样使用npm install –global glup全局安装gulp组件,或作为项目开发依赖使用--save-dev glup安装。接着在项目的根目录下新建gulpfile.js的文件,写入glup.task(default, function(){})来定义任务,并通过glup命令执行。还可以通过glup <task1> <task2>执行系列任务
常用API
为了简化用户的使用难度,gulp的API用法很简洁,数目也很少。
gulp.src(globs[, options])。输出符合glob匹配模式或匹配模式数组的文件,并返回一个stream可以被pipe方法传递到别的插件中。Glob的写法和Grunt类似。Options中可以选择buffer, read, base等属性,更改读取格式等。以下是样例。
gulp.src('client/templates/*.jade')
.pipe(jade())
.pipe(minify())
.pipe(gulp.dest('build/minified_templates'));
gulp.dest(path[, options])。可以被pipe进来,将会写入文件,且重新输出所有数据。因此可以继续将它pipe到多个文件。若文件夹不存在将会自动创建。样例如下:
gulp.src('./client/templates/*.jade')
.pipe(jade())
.pipe(gulp.dest('./build/templates'))
.pipe(minify())
.pipe(gulp.dest('./build/minified_templates'));
gulp.task(name[, deps], fn)用来定义一个使用orchestrator实现的任务。name指定任务名,deps指定任务列表数组,这些任务会在当前任务之前完成。fn表示任务要执行的一些操作。在fn接受一个callback,返回一个stream或返回一个promise时,允许任务异步执行。默认下,gulp会一次性运行所有task且不做等待。因此,若想创建一个序列化task队列,需要1)给出提示告知task依赖另一个task完成。样例如下:
var gulp = require('gulp');
gulp.task('one', function(cb) {
//do something
cb(err);
});
gulp.task('two', ['one'], function() {
// 'one' finshed
});
gulp.task('default', ['one', 'two']);
gulp.watch(glob[, opts], tasks)或gulp.watch(glob[, opts, cb])。监视文件,并在文件改动时做一些事情。它会返回一个EventEmitter释放change事件。其中tasks为在文件变动后执行的一个或多个gulp.task()名字。用法如:
var watcher = gulp.watch('js/**/*.js', ['uglify','reload']);
watcher.on('change', function(event) {
console.log('File ' + event.path + ' was ' + event.type + ', running tasks...');
}); 后者的用法则是,在cb中指定每次变动需要执行的callback。这个callback会被传入一个event对象描述监控到的变动。有如path, type这样的属性。其中type表示变动类型,有added, changed, deleted等。
gulp.run可以最大并行化执行系列的任务列表。
CLI使用
常用的gulp参数很有限。-v显示gulp版本,--require <path>在执行前require一个模块,可以多次使用,--gulpfile <path>手动指定gulpfile路径,--cwd指定gulpfile开始查找的位置,--tasks显示task依赖树。--color强制显示颜色,--no-color强制不显示颜色,--silent禁止所有日志输出。
task通过gulp <task name>来执行。只执行gulp,则会执行注册名为default的task.
更多
Gulp是基于流的自动构建系统。相对grunt结构简单,学习成本低。文件里存放代码而非配置。作者的幻灯片里做了简明扼要地解释。想要更深入的学习,可以参加中文版的stream-book对nodeJS流的介绍。在杂项里的"Nodejs中的Stream"也有做的笔记。
CommonJS
简介
CommonJS的目标是在浏览器环境外构建JS生态系统,出现于2009年。官方的JS标准API是为了构建基于浏览器的应用程序,这限制了JS的更广泛应用。CommonJS定义了更多普通应用的API,它的终极目标是进行JS模块化,把JS提升到类似于Python、Ruby、Java的地位。只要环境兼容,使用CommonJS API编写的应用程序就可以通用。
而实际上,NodeJS就是CommonJS模块化规范的一种实现。规范还在不断的发展中。以下展示部分内容
特点
- 一个文件就是一个独立的作用域,只能通过global共享(不推荐)
- 通过
exports定义对外接口,通过require加载此接口 - 模块可以多次加载,但只在第一次加载时运行并缓存。
- 模块加载的顺序和代码中出现顺序一致。
Module
每个模块内部都有一个module对象,对象有id, filename, loaded, parent, children, exports等属性。这些在nodeJS中都有实现。
module.export用于向外导出模块信息。Node中为每个模块提供了一个exports变量预绑定到module.export上,通过exports.xxx的形式导出。破坏这个绑定关系的操作都将使exports变量无效。
Require
require用于加载模块文件,它会读入并执行一个Javascript文件,然后返回exports对象,如果未发现指定模块会报错。同时,加载的模块的输入时被输出值的拷贝。
require加载模块时,默认为js文件。若路径以/开头表示绝对路径,以./开头表示相对路径,否则node会去node_modules目录下查找。使用require.resolve可以看到确切结果。在找到目录后,会将package.json中的main对应的值作为入口文件。
require进来的模块会放在缓存中,不会多次加载。若想多次执行同一模块,可以用module.exports导出函数,或delete require.cache[moduleName]
模块循环加载时,会先加载不完整的版本,在都require进来后,通过缓存读取exports避免不全的问题。
AMD and more?
CommonJS主要是为JS在后端表现定制的,而浏览器和服务器端的特点是不一样的。AMD的规范主要为前端JS表现定制。前者加载模块是同步的,后者是异步的。
AMD规范使用define方法闭包定义模块,格式类似于
define(id?: String, dependencies?: String[], factory: Function|Object);id是模块名,可选。dependencies是依赖模块列表。function是模块的具体实现,它的返回值就是模块的输出接口或值。范例如下:
define('myModule', ['jquery'], function($) {
return $('body').text('hello world');
});
define(['myModule'], function(myModule) {});
其中function的输入参数即为依赖模块的输出。通常将没有id的匿名模块作为应用的启动函数。
AMD规范允许输出模块兼容CommonJS规范。
RequireJS就是采用了AMD规范的用于模块以来的工具,使用方式同上面的范例。正如AMD名字中提到的那样,它异步引入所有的依赖模块,减少的导入的时间。同时也会因此出现隐式的难以发现的错误。与之并列的还有基于CMD规范的SeaJS,主旨所限,从略。
更多
CommonJS实际上是JS模块化的一种体现。这也是JS发展的趋势。关于JS模块化编程的介绍见模块的写法,AMD规范,require.js用法。这三篇博客系统地讲解了模块化的思路和应用。另外还有CommonJS,AMD,CMD对比,AMD使用样例,Node中CommonJS的部分实现可以参考。
Backbone.js
概述
MVC框架是代码组织的经典模式,便于团队协作进行开发。M、V、C分别代表Model,View和Controller。同样在Javascript的社区中,也有着许多MVC和MVC变体框架MV*(下面介绍的AngularJS等)。框架的优点在于便于分工和和代码维护,缺点在于限制了代码的写法,且学习成本一般较高。
Backbone.js提出于2010年,它严格来说并不算是MV*框架,而是借助一些功能模块的帮助快速构建一个单页面Web应用。因此它给用户了很大的自由在Model和View的连接上。从它的API结构就能看出,Model和View部分是较重的,Controller部分则只由router和router对应的controller处理函数构成。相对来说,backbone.js的体积很小,且学习成本较低。
根据官网介绍,underscores.js(一个功能型js函数库)是backbone.js的强依赖,jquery和json2.js是backbone用于Backbone.View的依赖,但是有类似Zepto等替代方案。因此在使用backbone.js时,通常要引入这四个文件。
项目组成
一般来说,一个backbone.js的应用,由models, views, collections, controllers四部分组成。其中models用来描述数据的一个基本单位。如下:
App.Models.Person = Backbone.Model.extend({
defaults: {
"name": "foo",
"value": "bar"
}
}); Colletions是同一种model的集合,可以方便地表示列表等展示方式,如下:
App.Collections.Grade = Backbone.collection.extend({
model: App.Models.Person
}); 上面的代码表示,Grade这个集合由Person单元组成。View部分用来在页面上呈现数据,呈现中涉及到绑定DOM的工作大多由jquery完成,View部分必须有el属性,指定绑定的DOM节点,events指定监听事件和对应方法,initialize和render方法分别完成初始化和渲染两个步骤。
App.Views.Medals = Backbone.View.extend({
el: "#list",
initialize: function() {
this.listenTo(Person, 'change', this.render);
this.listenTo(Person, 'destroy', this.remove);
this.render();
},
render: function() {
var template = _.template($('item-template').html());
this.$el.html(template(Person.Medals.toJSON()));
},
events: {
"click .toggle" : "toggle",
"dbclick .view" : "edit",
"click a.destroy" : "clear",
"blur .edit" : "close"
}
}) 控制器一般用来相应路由的结果,定义比较自由,例如下面的形式:
App.Controllers.show = function(id) {
var p = new App.Models.Person({id: id});
p.updateTime(Date.now());
p.fetch(function(model,response,options){
var view = new App.Views.Medals({medal: p});
});
}; 最后路由方面。通过继承backbone的router模块实现:
var paths = Backbone.Router.extend({
routes: {
"" : "wholeApp",
"users/:id" : "usershow",
"users/:id/p:order" : "ordersIndex"
},
wholeApp : App.Controller.default,
usershow : App.Controller.show,
ordersIndex : App.Controller.orderBy
});
new paths();
Backbone.history.start({pushState: true});
在定义好路由部分后,通过backbone的history模块的start方法启动路由即可。一个基于Backbone.js构造的项目结构大抵如此,它们可以位于同一个文件下(一般案例完全可以这么做)甚至位于html的script标签内。诚然这便于中小型项目,尤其是单页面逻辑内容丰富的Web应用开发使用,不也和当前流行的组件化、模块化的js开发风格有所不同。目前backbone.js仍然在1.x版本,可能会在2.0版本后采用ES6的原生模块化方案等新js特性吧。
API介绍(v1.3.3)
Backbone官网对它的API有着详细的介绍,且页面风格与Zepto、underscore一致,非常便于阅读和检索。
View
Backbone.View的方法用来定义视图类,其中最根本的方法extend拓展定义一个视图类,类的内部通常由render方法渲染界面,渲染时使用类jquery的语法,插入一些html比群标签或计算后的内容。定义好视图类后,通过新建视图实例的形式运行,得到结果,新建时,有时需要指定Model。
在需要用到模板时,可以先通过underscore(简写符为'_')的template方法导入模板为函数。模板通常建议用<script>并指定type=text/template的定义在html文档中,并用jquery的语句获取。导入模板后,可以把数据的json格式输入到函数中。
extend(properties[, class properties]):用来创建视图类,有时不在配置中指定el,而通过tagName或是className指定列表中的各元素initialize([options]):在实例化视图类的时候调用,可以写入el的属性。el属性:指定视图所绑定的网页元素(通常用在单例视图类中),$el则表示el所对应的jquery对象。tagName, className属性:见上面介绍template方法:通过_.template(xxx)指定网页模板生成模板函数,在render中渲染。events属性:指定视图中的事件及其对应的处理函数
另外,还有setElement更改el,remove移除el和jquery自带的一些方法可以使用。
Events
Backbone.Events是一个事件对象,任何继承这个对象的对象,都具有Backbone.Events接口,可以使用on和trigger等方法,发布和订阅消息。
// use extends
var EventListener = _.extend({}, Backbone.Events);
//use clone
var Dispatch = _.extend(Backbone.Events);
on(event, callback, [context])方法。可以将回调函数绑定在对象的一些事件上,并可以通过off方法取消绑定。once方法绑定的事件只触发一次回调函数。trigger(event, [*args])可以触发特定事件。listenTo(other, event, callback)可以把对象绑定在其他对象的事件上,经常用在View视图类中。如view.listenTo(model, 'change', view.render);
Backbone提供了许多内建的事件,如add, remove, update, change, reset, change:[attr], destroy等,更多的参加官方文档。
Router
Router是backbone提供的路由对象,用于将用户请求的url和后台函数一一对应。同样,它也通过extend方法定义。
routes属性:通过键值对形式指定路径和函数名。空字符串代表根路径,*代表任意路径,同时也可以通过":"设置路径参数,这些参数会被捕获并传入处理函数。同样可以用route函数一条条定义路由。navigate(fragment, [options]):调转到新页面,这是trigger和replace属性可以保留url和浏览器记录。execute(callback, args, name):在每次路由时都会调用,通过callback的返回值是否为真,判断是否调用处理函数,如下:
var Router = Backbone.Router.extend({
execute: function(callback, args, name) {
if (!loggedIn) {
goToLogin();
return false;
}
args.push(parseQueryString(args.pop()));
if (callback) callback.apply(this, args);
}
}); 路由类设置好后,实例化之,并通过Backbone.history.start()启动。通常需要指定pushState为true。如果应用程序不在根目录,还需要设置root值。
Model
Model代表单一的对象。和Collection一起组成Model层。Backbone.js并不要求Model的数据位于本地,在使用fetch()等操作时,backbone的sync方法默认会用jquery的get方法等去获取。所以,很多本地存储数据的应用会重写Backbone.sync函数。
Model依旧使用extend方法生成类,和view类似使用new创建实例,可以在defaults属性中设置默认属性。在生成实例时,需要提供各属性的具体值,且需要有主键字段,便于和MangoDB等数据库互动。
get(attr),set(attr,[options])分别用来获取和设置该实例的值。在有特殊字符防止xss时,推荐使用escape方法代替get方法。has(attr), unset(attr,[options]), clear([options]):分别检测是否有某属性,删除某属性和删除所有除id外的属性,options中可以指定silent,不触发change事件。另外,属性可以直接通过attributes访问。idAttribute属性:指定作为主键的字段。可通过id访问。toJSON([options]):将该实例json化,常和View.template配合使用。fetch([options]):通过jquery发起XHR请求,获取model数据。在options中可以分别指定success和error的回调,回调分别接受model, response, options。使用方法如下:
var user = new User ({id: 1});
user.fetch({
success: function (user){
console.log(user.toJSON());
}
})save([attr], [options]):通知服务器新建或更新Model,如果Model实例不含id属性,将使用POST新建,如果Model带有id属性,save方法将使用PUT更新实例。options和fetch用法类似。validate(attr, [options])检测属性是否合法会,触发invalid事件。isValid()方法会执行validate返回是否合法的结果。另外destroy方法清除一个实例,clone拷贝一个实例,hasChanged检测属性是否已更新。Underscore关于对象的如keys,pick等方法也可使用。
Collection
Colletcion是同一类Model的集合,如Model是学生,Collection就是班级;Model是歌,Collection就是专辑。如下面代码所示:
var Song = Backbone.Model.extend({});
var Album = Backbone.Collection.extend({
model: Song
}); add(models, [options]), remove(models, [options]):将new出来的实例直接放入Collection的实例,或通过id字段值移除Model实例。get(id), set(model, [options])获取collection中的某个model,或重设整个collection。在重设时通过融合的方式完成。model([attrs], [options])指定collections所包括的Model。modelId属性指定Collection标记Model的方法,函数接受attrs。多用在不同idAttribute的情况。comparator指定排序Model的标准字段。sort([options])方法会跟这个属性来排列Models。pluck(attr), where(attr)取出所有Models的某一列,返回满足where条件的所有Model。findWhere(attr)返回第一个满足条件的结果。fetch([options])类似Model中的用法,获取整个Collection。create(attr, [options])通过Collection创建一个Model。
此外,underscore和原生用于数组的方法如push, pop, shift, unshift, forEach, every等等函数也可以使用。
Demos
由于Backbone.js并非使用模块来构建Web应用,且自由度很高,结合上面介绍的API,可以方便地构建很多单页面应用。官网也提供了许多demos,便于初学者上手掌握。
可以先从Hello-backbonejs上手,感受backbone的基本使用。之后学习Todos(系列的TodoMVC也是很不错的学习Angular,Ember.js等的demo),就可以开始自己捣鼓点小东西了。个人认为对比下面介绍的框架,已经好上手很多了。
更多
Backbone.locaStorage也是很常用的backbone的插件,用于将Model和Collection的数据插入到本地存储中,根据介绍,使用很简单:
window.SomeCollection = Backbone.Collection.extend({
localStorage: new Backbone.LocalStorage("SomeCollection"), // Unique name within your app.
// ... everything else is normal.
}); 另外很喜欢官网的style,和underscore以及zepto的一样,简约而便于检索。本文的样式也参考自此。
Express JS
概述
Express是基于Node.js的流行Web开放框架,没有对NodeJS进行二次抽象。可以快速搭建一个完整功能的网站。后面我们将用一个例子简单展示express的特点。
新建一个项目目录,进入该目录新建package.json文件,填写项目的一些配置信息。包括name, description, version, dependencies等等。其中dependencies,/中可指定express的版本范围,如4.x. 执行npm install指令安装环境。
新建index.js,写入如下样例:
var express = require('express');
var app = express();
app.get('/',function(req, res){
res.send('Hello, world!');
});
app.listen(8888);
即可在浏览器看到页面效果。其中app.get对路由的处理还可以拓展到其他路径,封装成路由模块。
基本原理
Express框架建立在nodeJS内置的http模块上。上面的app实际上就是由http的createServer方法生成的。而express只是做了一层包装。
中间件是处理http请求的函数。多个中间件按照流水线的形式处理请求,单个中间件处理完成后,通过调用next方法交给下个中间件处理。next方法所带参数表示抛出错误。可以通过use方法注册中间件。样例如下:
var express = require('express')
var http = require('http');
var app = express();
app.use('/home', function(req, res, next){
res.writeHead(200, {"Content-Type": "text/plain"});
res.end("Welcome!");
});
app.use('/about', function(req, res, next){
res.writeHead(200, {"Content-Type": "text/plain"});
res.end("About.");
});
app.use(function(req, res){
res.writeHead(404, {"Content-Type": "text/plain"});
res.end("404 error!\n");
});
app.listen(8888);
常用方法
除了上文中用到的use,/,对于一些特殊的use使用,还有别名的方法。如all方法表示所有满足第一个条件的请求都必须通过该中间件,*则表示所有请求都必须通过。get方法和post, put, delete等方法也类似,它们没有next方法,只要一个中间件被调用,后面的中间件就不再调用。注意,app.get(name)意为获取全局变量值。
这些方法的第一个参数都是请求的路径。Express允许模式匹配,即可以在路径中匹配并捕获模式字段,字段后加上?表示模式可选。范例如下:
app.get('/hello/:who?', function(req, res){
if(req.params.who) res.end("Hello " + req.parmas.who + "!");
else res.send("Hello guest.");
}); url匹配还支持正则匹配。范例略。同时,set方法可以为系统变量指定新值。
response对象也有一些常用方法。redirect方法用于网页重定向,sendFile用于发送文件,render用于渲染网页模板,向模板中传递数据。Request也有着许多常用对象,ip用于获得请求的ip地址,files用于获取上传的文件。
搭建https服务器的方法略。更多API见官方文档。
网页模板
通常,对于大部分请求,返回的结果都为较复杂的网页,此时使用send方法就不再方便。展示静态网页模板时,使用response对象的sendFile方法可以解决此问题。渲染动态网页可以使用render方法,也可以利用一些模板引擎完成。
在模板中通过{{}}(因模板而异)加载动态数据。模板后缀,视图模板存放的路径,渲染引擎入口等可以在入口js处统一声明。
静态文件通过express.static方法指定路径,在浏览器发出非HTML文件请求时,去指定的目录寻找。
路由
在4.0后,express将路由功能封装成了一个单独的组件Express.Router。同样拥有use, get, param, route方法。用法和app极为相似。方便通过app.use(xxx, router)的形式挂载不同的根目录。route方法以路径作为输入参数,之后跟post或其他方法绑定到该路径上。注意,router中的use中间件须放在HTTP动词方法之前,否则不会执行。
app同样有route属性,app.route是express.router()的等价形式。
常用模块
使用Express快速开发网络应用的时候,会用到许多现成的模块辅助开发。它们能在express的组织下方便地完成各种功能。
body-parser是express的处理请求体的中间件。它接受stream格式的request体,并以用户需要的格式友好地返回。以下是一些body-parser提供的API。
bodyParser.json(options)解析json格式的请求体,接受Unicode编码的请求提,支持gzip和deflate格式。req.body会被解析后的body替代。
bodyParser.raw(options)将请求题以Buffer类型解析。返回的解析器将请求体解析为buffer格式。bodyParser.text(options)类似,解析为string格式。
bodyParser.urlencoded(options)只解析urlencoded请求体,接受UTF-8编码。生成的新的请求体是键值对的格式。
这些API可以按顺序多次列写,依次尝试解析直到body体被成功解析为止。更多信息见官方解释。
cookie是用来解决HTTP协议无状态的问题的。Cookie通过服务器发往客户端浏览器,在浏览器每次发起请求时附带,有path, expire, maxAge, secure, httpOnly等参数。
Express-session
为了保证cookie的安全性,session因此诞生。Session通过sid标识,通常储存在cookie中,服务器每次接收到请求,将session id对应的data关联,进行相应操作。Session可以存放在1) 内存2) cookie 3) redis, memcached缓存 4)数据库中。
Express中操作session用来这个模块主要通过session(options)初始化并作为处理回话(session)的中间件。Options中的主要参数有name,用来指定cookie中保存session的字段名,store指定session的存储方式,secret指定hash加密cookie的方式,cookie指定存放sid的cookie的相关选项,genid指定生成新sid时用到的函数,rolling指定每个请求是否重新设置一个cookie,resave指定session未更改时,是否保存session值。
Connect-mongo
这个组件是用来方便地将用户session存储在mongodb中的。通过require(xxx)(session)引入后,如session(new MongoStore(opts))这样使用。opts里可以通过Mangoose或其他驱动器或url指定MondoDB服务器。详情见github api解释
Ejs
实际上ejs严格来说是一个模板引擎,负责将模板文件替换成html文件再发回到客户端。ejs有三种标签。<% code %> <%= code %> <%- code %>分别对应JS代码,可以通过使用for循环显示列表内容。ejs还可以使用<%- include a %>引入其他模板从而实现页面布局的效果。
个人认为jade模板引擎Markdown式的写法更简洁。
Mongodb
Node开发经常使用的MongoDB做数据库。MongoDB是Mongo在node.js中的驱动。在2.x版本的mongodb中,通过MongoClient.connect(url, opts, callback)创建和数据库的连接,其中callback可以读取err和db对象,从而对数据库操作。通过db.collection(name)获取指定集合,使用得到的collection的insert, insertMany, find(quert), sort, limit, update, delete完成增删改查。使用toArray可以把查询的数据转成数组格式。
更多Mongodb使用参见node-mongodb API文档.
Connect-flash
flash使用session的特殊区域。信息在展示前被写入flash,展示给用户后即被擦除。Flash常用于跳转页面,保证信息能够正确传递到下一个被渲染的界面。
使用时,在初始化session后,创建flash中间件即可。在页面即将跳转时,写入信息到req.flash中,在跳转的页面里,即可通过req.flash获取到。
更多
在实际开发中,通常综合了许多的模块。惯例下,在bin目录下放置可执行文件,models目录下放置模型定义和与数据库沟通的文件充当Model部分,node_modules放置依赖包,public放置静态文件包括css文件等,routes放置路由文件充当Controller部分,views放置视图模板作为View部分。父目录下还有app.js作为入口文件,package.json作为项目配置文件,settings.js储存常用设置参数如数据库端口等。
Express有着丰富的模块可供选择,模块文档可以在npm和github上找到,这些模块可以帮助你轻松完成复杂功能,让开发者专注于工程结构和代码逻辑。以上的笔记来自阮一峰博客和开发简单博客的实例。
React JS
What and Why
React起源于facebook的内部项目。起初用来搭建Instagram的UI界面,渐渐地发展为前后端都有的网络应用解决方案。React作为开发UI界面的库,特点十分明显。
- 组件化,react允许将代码封装成一个个组件,然后像插入HTML标签一样,在网页中插入这个组件。在定义好组件后,要做的只是组建的复用和组合。
- 组件就像台有限状态机,用户交互改变状态变化,自动触发重新渲染。组件的生命周期内,有特定处理函数去处理状态变化,并更新改变的部分。这在页面数据经常更新时,会非常方便。
关于它还有些需要明确的东西。首先,React并不是一个完整的MVC框架,它和MVC中的V更像;react也并不是一种新的模板语言,没有JSX的React也能正常工作,JSX是为那些更偏好HTML写法的人准备的。React提供了服务器端的Render能力,但实际上这并不是它的核心出发点,事实上React官方教程是以浏览器端应用介绍为主的。
Thinking in React Way
使用React可以快速构建Web应用程序组件。在使用React构建一个产品时,通常有如下几步:
- 拆分界面为一个组件树,理想状态下一个组件应该只做一件事,当功能较大时就需要拆分成更小的子组件。
- 利用React创建一个静态版本,不考虑交互功能,只将数据模型渲染在UI上。在这个过程中,将会构造一些组件,这些组件重用其他组件,并通过props传递数据。注意,这里不用到state,state用来实现交互功能。
- 为组件设计最小完整state,
state使得交互触发底层数据模型的变化。考虑设计中的所有数据片段,从父级传入的,不随时间变化的,根据其他props和state算出的多半不适合做state。 - 确定state的生命周期,在上一步确定作为state的数据片段后,需要确定改变或拥有这些state数据的组件。因为React中数据沿着组件树从上向下单向流动,通常,选择基于state渲染节点的组件的共同祖先组件维护这个state。
- 添加反向数据流,在上面的步骤后,数据流已经基于
props和state沿组件树从上到下单项渲染。层级较深的组件需要更新state时,需要祖先组件传递一个回调函数,在特定事件时触发。
数据呈现
用户界面做的最多的就是数据的呈现。React让呈现更简单,且数据变化时,用户界面自动更新。例子见reactjs-demo的hello-react。
React并不会去操作真实DOM(除非必要),它用一个快速的内置虚拟DOM元素呈现改变来达到高效率。组件的数据输入称为props,通过JSX语法传递,且只读。React组件就像是函数,接受props和state做参数,渲染单个HTML节点。
MVC模型中通常将模板显示和数据逻辑分离开,React开发者认为这样会产生过多代码。因此,React的解决方案是通过Javascript直接生成模板,允许在js中使用HTML语法,这种js和HTML混用的语法被称为JSX。JSX和HTML很像,在babel的帮助下,可以在多种环境下使用JSX。
React不强制使用JSX,完全可以使用React API(React.createElement)和原生Javascript创建React元素。方便起见,可以通过工厂方法React.createFactory()创建自定义组件。React已经为HTML标签设置了内置工厂方法。
JSX
JSX很像XML的Javascript的语法拓展,通过React可以做JSX的简单转换。虽然不强制,但是React建议使用JSX语法。XML标签的语法可以使组件关系更加清晰,比方法调用和字面量的形式可读性更好。
React可以渲染HTML标签(string)和React组件(classes),其中前者需要在JSX中使用小写字母开头的标签名,后者需要创建一个大写字母开头的本地变量(使用时是也是大写字母开头的标签名)。这是React约定俗称的。需要注意的是,JSX中的一些标识符如class和for替代为className和htmlfor(它们是js的保留字)。
React会将类XML语法的JSX转成纯粹的Javascript,XML元素,属性和子节点会被转换成React.createElement的参数。JSX同样允许类似XML的方式定义子节点。示例如下:
var Nav, Profile;
// React Input (JSX):
var app = <Nav color="blue"><Profile>click</Profile></Nav>;
// React Output (JS):
var app = React.createElement(
Nav,
{color:"blue"},
React.createElement(Profile, null, "click")
); 上面代码中,Input和output的语句是等效的。JSX还将从变量名中设定组件的displayName,若使用React.createClass时没有指定displayName的属性。
V0.11.0后,React支持命名空间组件,当构建一个有许多子节点的组件时,可以通过设置父组件的命名空间避免过多的变量定义。在定义时,使用类似于FatherComponent.son = xxx的形式定义。
Javascript表达式在JSX中使用一对大括号{}包裹,不使用引号。组件中的提及的属性默认为true,未提及的属性默认为false。子组件也可以作为表达式使用。
JSX属性扩散与HTML
若事先知道组建的全部属性(props),JSX可以很轻松地定义组件。同时,如果不知道应该设置哪些props,最好不要设置它。JSX的新特性属性扩散支持通过{…props}的形式将属性传递进组件内。它可以多次使用,且可以和其他属性一起使用,后面的属性会覆盖前面的。语法类似下面:
var props = {};
props.foo = x;
props.bar = y;
var component = <Component {...props} />;
...操作符实际上也是ES6新规范中的新特性。
JSX中可以插入HTML实体,但JSX会对所有字符串做二次转义,避免XSS攻击。最简单的方法是直接使用Unicode字符,或者通过\u00xx的形式插入Unicode字符,万不得已,可以在div的dangerouslySetInnerHTML的属性里直接指定原始HTML。
可以为原生HTML元素指定自定义属性,但需要在属性前加上data-的前缀,否则React不会渲染它们。然而自定义元素支持任意属性表示网络可达性的aria属性会被正确渲染。
添加交互
React用state记录因用户交互改变的组件状态。把事件处理器以驼峰命名形式当作组件props传入即可,就像使用普通HTML一样。在背后,React把事件回调隐式绑定在它的组件实例上,减少了用户的代码量。实际上,React也并没有把事件处理器绑定在节点上,而是用一个最外层的唯一事件监听器处理和分发事件,分发时根据组件在内部映射的事件处理器做处理。
如之前提到的,可以把用户界面的组件想象成状态机,React只需更新组件的state,然后根据state重新渲染界面,无需操作DOM。常用的通知React数据变化的方法是调用setState(data, callback)合并data到this.state中,触发重新渲染。
实际上,大多数的组件完成的工作只是从props里读取数据并渲染,但是在需要响应用户操作、服务器请求或时间推移时,state是需要的。React建议将尽量多的组件无状态化,这样可以减少冗余,更好描述组件业务逻辑。因此,通常的模式是创建多个只负责渲染数据的无状态(stateless)组件,并在它们上层创建一个有状态(stateful)组件,这个组件封装了所有的用户交互逻辑,而它的无状态子组件负责声明式渲染数据。
承接上文,由于React会根据state自动渲染,因此尽量只把组件的状态原子化,会避免经常性的手动保持数据同步。计算所得数据、React组件、基于props的重复数据不建议包括在state中。总结下来就是,state内储存的数据相互独立且和props的数据相互独立。
组合组件
上面的介绍都局限在但各组件内,React里能通过开发简单组件将程序的不同关注点分离,获得类似于使用函数和类的好处。官网提供的Avatar组件例子清晰易懂:
var Avatar = React.createClass({
render: function() {
return (
<div>
<ProfilePic username={this.props.username} />
<ProfileLink username={this.props.username} />
</div>
);
}
});
var ProfilePic = React.createClass({
render: function() {
return (
<img src={'http://graph.facebook.com/' + this.props.username + '/picture'} />
);
}
});
var ProfileLink = React.createClass({
render: function() {
return (
<a href={'http://www.facebook.com/' + this.props.username}>
{this.props.username}
</a>
);
}
});
React.render(
<Avatar username="pwh" />,
document.getElementById('example')
); 从上面的例子看到,组件的拥有者为组件设置props,反之亦然。同样的道理,组件无法修改自己的props。React中,从属关系和父子关系是两个不同的概念。上一个例子中,Avatar是div、ProfilePic和ProfileLink的拥有者,div是ProfilePic和ProfileLink实例的父级。
在React组件实例化时,可以在闭合标签内引用其他组件或javascript表达式。通过this.props.children这个props读取子级。每次render后,React会根据子级的渲染顺序校正子级。当状态化组件需要删除组件时,通常采用设置display: none来解决。React里,数据通过上面介绍的props从拥有着流向从属者,这就是React中的单向数据绑定。拥有者可以通过props和state计算出一些值,然后将结果绑定在从属组件的props上。结合ES7的实验特性,使用var {x, y, …other}=this.props(解构赋值)定义组件props,把未知属性批量提取出来,避免传递不必要的props给子组件。
随着应用不断拓展,确保组件正确使用很重要。React.propTypes提供了很多验证其来验证传入数据的有效性,如React.PropTypes.element可以限定只能传入一个子级。当props接收到无效数据时,Javascript控制器会抛出警告。出于性能考虑,通常只在开发环境验证propType。官网教程给出了propType的各种用法,在使用时,propTypes需要写在组件的属性里。getDefaultProps属性支持用声明式的方式定义props的默认值。保证父级未传入props时,this.props.value有默认值。利用JSX的属性扩散语法,可以轻松传递props,就像下面这样:
var CheckLink = React.createClass({
render: function() {
return <a {...this.props}>{'√ '}{this.props.children};
}
});
React.render(
<CheckLink href="/checked.html">
Click here!
</CheckLink>,
document.getElementById('example')
); 组件间有时也需要共用一些功能,React使用mixins解决这类问题。在mixins定义好之后,通过指定组件的mixins属性,并用[]包裹引用mixin。另外,利用ES6的js新特性class定义,可以使用class HelloMessage extends React.Component定义组件。
表单组件
React的表单组件支持几个受交互影响的属性: value, checked和selected。组件可以通过onChange回调函数监听组建变化。设置了value的<input>是一个受限组件,渲染出来的HTML始终保持value属性的值。没有设置value的<input>组件是一个不受限的组件,渲染的元素直接反应用户输入,可以通过defaultValue设置初始值。同样地,radio,checkbox的<input>支持defaultChecked属性,<select>支持defaultValue属性。
设置受限组件和不受限组件是因为React的组件实际上反映了视图在任何时间点的状态。所以既然明确写出value=xxx,那么输入框的值在任何时间点被渲染都应该不变。另外,textarea和select标签也使用value和defaultValue方便进行组件控制。
组件说明与生命周期
组件通过React.createClass创建(ES6新特性下,继承component类亦可)。
render方法是必须的,它应该是纯粹的,不修改组件state,不涉及交互,每次调用返回相同信息。getInitialState方法在组件挂载前调用,设置this.state的初值。getDefaultProps在组件创建时调用一次,返回值被缓存下来,用于父组件遗漏props,这个方法不能依赖this.propspropType对象允许验证传入组件的propsmixins对象允许使用mixin来在组件间共享行为。statics对象允许定义静态方法在组件类上调用displayName字符串输出调试信息
组件的生命周期分为三个阶段:挂载、更新、移除。React提供生命周期方法,其中will方法在某些行为发生前调用,did方法在某些行为发生后调用。
挂载:组件被插入到DOM中。getInitialState()方法在组件挂载前调用。状态化组件需要实现这个方法,返回初始的state数据。componentWillMount()在前,componentDidMound在后。
更新:组件被重新渲染,查明DOM是否应该刷新。
componentWillReceive(obj nextProps)当一个挂在组件接收到新的props时候被调用。该方法应该用于比较this.props和nextProps的不同来判断是否使用this.setState()来改变state。shouldComponentUpdate(o- bj nextProps, obj nextState): boolean当组件作出是否要更新DOM决定时被调用,实现该函数优化this.props和nexProps以及this.state和nextState的比较,如果不需要更新,返回false。
componentWillUpdate()和componentDidUpdate()分别在更新发生前后调用。
移除:组件从DOM中移除。componentWillUnmount()在组件移除和销毁前被调用。
Refs
React从不直接操作DOM,它在内存中维护一个DOM描述,并通过描述快速计算差异然后更新浏览器中的DOM。另外,React实现了完备的虚拟事件系统,确保所有事件对象符合W3C标准。但是,React也提供了直接使用底层DOM API的途径。
通过React.findDOMNode函数可以通过DOM节点获取挂载在之上的React组件。通过his.refs.xxx指向一个声明了ref属性的组件。
另外,render方法返回UI结构时,有时会出现超出虚拟DOM限制的需求,在render返回的组件实例上调用某些方法。通常,这对于应用中的数据流是不必要的。因为这些数据流总是确保最新的props被传递到每一个从render()输出的子级上。React提供refs属性来满足一些特殊情况,如操作DOM表现形式,在非React环境下使用React等。
ReactDOM库提供了render()方法(不要和组件类的render方法搞混),在绑定组件类的同时返回元素的支撑实例。一般在最外层使用。
React支持非常特殊的ref属性,可以绑定到render()输出的任何组件上。这个属性允许引用render()返回的响应支撑实例。使用时通过this.refs.xxx来获取支撑实例。在最新的React版本中这种方式已经不推荐,而推荐使用下面的ref回调属性。
React支持在组件上绑定ref回调函数属性,这个回调会在组件被挂载后立即执行。被引用的节点将被传入作为输入参数,回调函数可以立即使用这个节点或者将之保存下来(this.xxx = input)为以后使用做准备。ref使用在DOM组件上时,会返回DOM节点,使用在React组件上时会返回组建对象实例。
React建议在通常情况下,使用props和state向子组件发送消息,在场景不那么reactive时,使用refs。Ref的优点在于1)可以通过它调用组件类中的公共方法; 2)方便可靠地管理DOM; 3)Ref被自动管理,会和实例同生共死,不用考虑内存问题。在使用时,要注意以下问题:1)不要在render()方法中访问refs; 2)尽量通过在父级使用state避免refs的过度使用。
API
React JSX语法所提供的完全可以由React的API调用所替代。下面是react一些API的reference(主要摘自官方文档)
React
React是React库的入口。使用预编译包时,React是全局的;如果使用CommonJS的模块规范,则通过require引入。
Component是定义React组件的基本类,通过ES6的新特性,可以通过extends定义自己的组件类。
React.createClass(specification)方法创建一个组件类,并给出定义。定义中必须给出render方法。组件定义和声明周期参见别节。React.createElement(type, [props], [children ...])创建一个指定类型的ReactElement,type可以为DOM原型或ReactClass。React.createFactory(type)返回一个可以生成指定类型ReactElement的函数。React.cloneElement(element, [props], [children ...])克隆一个已有的元素,并融合进新的props,是新增特性
除此之外,还有isValidElement判断是否是合法元素,DOM方法更方便地创建DOM元素,PropTypes方法方便表单检验。React的Children对象提供了对props.children数据结构处理的工具,有map和forEach(与array的同名方法类似),以及count计算总数、only返回children仅有的子级元素和toArray方法将children数据专转为数组结构。
ReactDOM
ReactDOM包使用在React应用的最外层,用于进行网页原生DOM操作(虽然官方不推荐),其中render方法时最为常用的。ReactDOM.render(element, DOM container, [function callback]) React用于将组件绑定在DOM上,若已被绑定,则会更新。在绑定时,会将DOM原内容清除。React预计会在未来支持将多个组件类绑定在同一个DOM内。
unmountComponentAtNode(DOM container)方法和findDOMNode(React component)方法分别用于移除DOM上的组件和找到组件所对应的DOM。其中后者是ref的替代用法(官方不推荐),且不能在无状态组件内使用。
ReactDOMServer
renderToString和renderToStaticMarkup方法用于将React元素渲染成HTML内容。其中后者不会添加额外的DOM属性。另外,两个方法都只能在服务器环境下运行。
Component
Component实例在渲染时创建,并在之后的渲染中重复使用。可以在组件方法中用this访问。唯一一种外部访问的方法是储存ReactDOM.render的返回值,在其他组件里还能通过refs来实现同一效果。
setState(function/obj nextState, [function cb])方法合并nextState和当前state,支持回调函数。绝不要直接改变this.state。另外,除非在shouldComponentUpdate()中实现条件渲染逻辑,否则,该方法触发一次重绘。replaceState方法和setState方法类似,区别在于该方法会先删除现有state。forceUpdate([function cb])用在this.props和this.state未改变而仍需要重绘时调用,在手动修改this.state时也是如此。在该方法触发重绘时,子组件也会重绘(官方不推荐使用该方法= =)。bool isMounted()方法判断组件是否已被绑定在DOM中,该方法多用在异步场景下。
setProps和replaceProps方法在新版本中已被删去。
标签/属性/事件
React支持几乎所有的html和svg标签,同时也支持所有标准属性。React中的属性都用驼峰命名,class和for属性改为className和htmlFor。React还添加了特殊的非DOM属性:
key作为唯一标识器,用于在渲染和差异检测时将顺序打乱后,确保组件还存在。ref,介绍略。dangerouslySetInnerHTML提供插入纯HTML字符串功能
React对浏览器本地事件也有封装,且保证了浏览器兼容性。需要时,通过nativeEvent属性获得底层浏览器事件。通过e.preventDefault()可以避免事件冒泡。React的事件处理器在事件冒泡阶段出发,通过在事件后添加Capture(如onClickCapture)可以在捕获阶段处理事件。包括剪贴板、键盘、鼠标、焦点、表单、选择、触摸、UI、鼠标滚轮、多媒体、图片、动画、渐变事件(html5标准后添加了许多)。具体参加官方文档介绍。
Flux/Redux
React为开发者提供了状态化组件的前端开发方式,这仅仅完成了MVC的V部分。Flux是Facebook提出了用于M和C部分的解决方案(实际上并不能称为M和C)。Flux是一种架构约定和架构模式。根据文章介绍一个Flux应用主要包含四部分:dispatcher,stores,views,actions。数据流在它们之间单向流动。如下图所示:
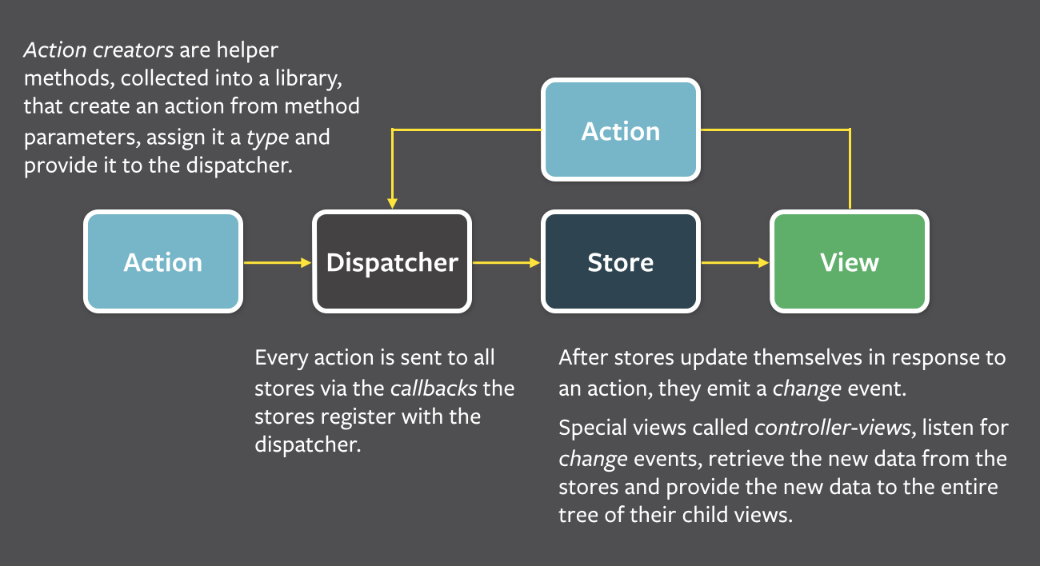
- 首先定义一些action creator方法。根据需要提供给dispatcher来分发。
- View部分通过交互触发Action。
- Dispatcher会分发出发的Action给所有注册的Store的回调函数
- Store回调函数根据Action的payload的部分更新自身数据,并触发一个change事件
- View会监听该事件,通过Store的方法拿到新数据,调用
setState更新组件UI
数据流在整个过程都是单向移动的,通过dispatcher来组织,由Store来维护所有状态。各部分分工明确。Dispatcher分发动作给Store注册的回调函数,官方提供了Dispatcher.js这个demo,与flux-todomvc作为使用样例。在样例中可以学到flux的简单使用。
Redux提出于2015年,充分利用函数式编程的特点,简化了flux的的用法。将flux中的action和dispatcher进一步解耦,且将dispatcher从store中解耦, store成为了stateless function(state,action)=> state。现在的store只管理状态,从而增强了其可拓展性。
在Redux中,action只是包含type和payload的对象,需要通过store.dispatch()方法来发送,action creator可以返回一个事件。Reducer用来处理action触发的对state的修改,形式类似于(oldState, action)=>newState。Redux将store视为唯一可信数据源,整个状态由一个store储存,由一个root reducer管理,在root reducer下,可以定义pure function管理状态树的各子树。
Redux的Store提供getState方法获取state,提供dispatch方法发送action修改state,提供subscribe()方法注册回调函数监听state的修改。总结起来,store.dispatch(action)触发事件,action的type和payload说明事件情况;action触发指定root reducer,根据type和payload返回一个新的state;所有通过subsribe注册的监听函数会被调用,它们可以通过getState拿到新的state。
更多
React仍然没有一个系统且用户友好的学习教程(循序渐进且有demo)。个人认为效率较高的学习方式是先由阮一峰的博客获得感性认识,再通过官方文档和中文文档的讲解获得全面认识。文档中也有demo展示。另外,React中文社区里会有一些不错的资源和讨论,React入门教程也有些补充,如Flux和Redux的介绍。
另外,React一直处在发展中,直到现在也未推出1.0版,且框架特点和使用方法和typical MVC框架差别较大,学习成本较高。在学习文档的同时根据"Tutorial"的介绍训练,效果会更好。
Angular JS
简介与安装
Angular是比较新的技术,1.0版本发布于2012年。它采用MVVM架构,和MVC架构的React不同,View和ViewModel有着数据的双向绑定。Angular现由Google正式支持。
Angular和React类似着眼点在前端的内容展示,不同于React尝试将UI界面组件化,Angular试图拓展HTML的功能来弥补与实际Web应用间的鸿沟。如:
- 通过
{{}}绑定数据 - 使用DOM控制结构迭代或隐藏DOM片段
- 将逻辑代码关联到DOM元素上
- 将HTML做成可重用组件
Angular具有很好的抽象性简化了应用的开发,且在CRUD应用中灵活性也很好,在DOM操作频繁且复杂的应用里,Angular并不适合。如游戏或是图形编辑器。这时使用React或者jQuery会好些。
Angularjs可以使用npm或者bower进行安装,bower/npm install angular。之后便可以在node_modules或bower_components中找到。在script标签中引入即可。
使用
应用/控制器
Angular在后台通过定义AngularJS module确定应用;在前端通过ng-app指定Angular应用所绑定的位置(通常是html标签)。应用的所有controller也由模块包含。后台应用通过angular.module(name, [])构造,前者确定应用名,后者确定依赖模块。
Angular支持创建自己的指令,使用app.directive(name, function(){})即可。自定义的指令可以通过元素名、属性、类名甚至注释来调用。在function部分的return中设置restrict为E A C M分别限制指令只能通过元素名、属性、类名、注释使用,可以叠用,默认为EA。
应用可以有多个控制器处理不同功能,后台通过app.controller(name, function(){})定义,前端通过指定ng-controller绑定。Angular控制器是对象类型,有属性和方法,都可以通过$scope访问,其他方法可以通过ng-click等命令绑定在前端标签。应用和控制器的后台js文件可以外部通过script标签导入,建议放在body后。
Angular表达式
Angular的表达式写在双大括号内,把数据绑定在HTML内,和ng-bind有一样的效果,Angular表达式和js表达式很像,可以包含数组,对象,字符串、数字、运算等等,但是不支持条件判断和过程控制,且支持过滤器。
数据模型
在controller中,可以为$scope变量赋值,从而定义应用的数据模型。在前端可以用ng-bind或{{}}使用已定义好的数据模型,或通过ng-model在前端输入域绑定数据。由于Angular采用数据双向板顶,修改输入域的值时,AngularJS的属性值也将同步更改。
指定标签ng-show属性,可以在后台结果返回为true时显示标签。ng-model还可以为应用数据提供状态值,通过$invalid, $dirty, $touched, $error访问。
同时在CSS类中,指定ng-invald, ng-empty, ng-not-empty, ng-touched, ng-un-touched, ng-valid, ng-dirty, ng-pending, ng-pristine类,可以让样式跟着模型状态改变。
过滤器
过滤器可以被添加在Angular语句中,用来格式化数据。有如下的一些可以选择:
currency格式化为指定货币;date格式化为指定日期;number格式化数字为字符串json格式化为json字符串filter筛选数组的子集limitTo限制数组或字符串指定数目的长度lowercase/uppercase格式化为大写或小写orderBy使数组按序排列
在使用时,通过一个管道字符 | 和一个过滤器添加到表达式中,如{{price | currency}}或{{x in names | filter: ’Bill’ | orderBy:’name’}}。filte支持自定义,在后台通过app.filter(name, function(){return function(){}})定义即可。
服务
AngularJS中,服务是一个函数或对象,以$开头,可以在应用中使用(注意服务需要作为一个参数传递到controller中,需要先传入后使用),用来构造一些常用或是复杂的操作。AngularJS内建有30多个服务。
$location服务返回当前页面的地址信息等,有absURL()等方法使用。$index记录着ng-repeat的序号。$timeout有类似于setTimeout的作用;同理$interval对应着setInterval函数。
$http是Angular应用最常用的服务,用于向特定位置发送请求,并通过then(function(){})获取返回。发送的方法有get/delete/head/jsonp/patch/post/put等。也可以直接通过类似如下的方式发起请求:
var app = angular.module('myApp', []);
app.controller('myCtrl', function($scope, $http) {
$http({
method : "GET",
url : "welcome.htm"
}).then(function mySucces(response) {
$scope.myWelcome = response.data;
}, function myError(response) {
$scope.myWelcome = response.statusText;
});
}); 返回值response有config, data, header, status, statusText等属性可以使用,可以在then方法的第二个参数指定错误处理函数。
另外,可以通过app.service(name,function(){})自定义服务对象,然后在控制器中使用。常用服务一节还列举了一些其他服务。
Sql
由于Angular是一个前端的框架,需要后台如PHP,ASP等的辅助才可完成和数据库的交互,解决跨域问题的方法从略。
DOM事件
ng-disabled和ng-show、ng-hide结合ng-model可以实现disabled和show/hide的效果。Angular还提供了许多DOM事件监听器。有ng-blur, change, click, copy, cut, dbclick, focus, keydown, keypress, keyup, mousedown, mouseenter, mouseleave, mouseover, mouseup, paste等。指定标签的这些属性即可为DOM事件绑定处理函数。Angular事件并不会重写HTML事件。
表单验证
Angular的数据双向绑定使得表单验证更加简洁,结合HTML5的新特性。required属性要求不能为空,type限制输入的数据类型。在输入域改变的同时,$untouched, $touched, $pristine(未被修改过)$dirty(已被修改过)$invalid $valid等状态也随之改变。表格则有$pristine $dirty $invalid $valid $submitted等状态。使用样例如下
<input name="myName" ng-model="myName" required>
<span ng-show="myForm.myName.$touched && myForm.myName.$invalid">The name is required.</span>
另外,在数据模型中一节已提到,Angular会新增CSS类在标签上,便于设置CSS样式。结合HTML5新属性,会有很不错的效果。在特殊情况,可以通过app.directive定义新的验证方法,添加在控制器的$parsers中,当输入域的值改变时做检验。具体添加方式可参见文档。
路由
AngularJS通常用来构造单页网络应用。因此,URL采用/#/name的形式。在后台指定应用的依赖模块ngRoute,并通过app.confi配置routeProvider服务,使用依赖注入引入routeProvider服务,通过when(path, object).otherwise(object)按顺序定义所有路由。其中when的第二个输入参数是路由配置对象,有如下的参数可以配置:
template: 直接在ng-view中插入简单的HTML内容templateUrl: 在ng-view中插入HTML模板文件controller: 在当前模板执行的controller函数,生成新的scopecontrollerAs: 为controller指定别名redireTo: 重定向地址resolve: 指定当前controller所依赖的其他模块
通用API函数
angular.copy复制变量;angular.element;方法可以将元素包装为jquery对象;equals判断两个变量是否相等;fromJson反序列化一个JSON字符串;isArray, Date, Defined, Element, Function, Number, Object, String, Undefined分别判断数据类型。merge方法合并两个变量;noop执行一个空函数。
依赖注入
依赖注入是一种软件设计模式,用来为代码的依赖关系解耦。如杂项里介绍的,在需要其他依赖通过依赖的对象创建并传入。在Angular JS中引入服务,实际上就是依赖注入的一种语法糖。以输入参数的形式注入了控制器的依赖关系。这一点可以通过控制器的$inject来访问到。
为了更好地理解,我们通过下面的代码创建一个注入器inject,来向函数中注入依赖:
var inject = {
dependencies: {},
register: function(key, value) {
this.dependencies[key] = value;
},
resolve: function(deps, func, scope) {
var arr = [];
for (var i = 0 ; i < deps.length ; i++) {
if (this.dependencies.hasOwnProperty(deps[i])) {
arr.push(this.dependencies[deps[i]])
}
}
console.log(arr);
return function(){
func.apply(scope || {}, arr);
}
}
} 其中dependencies属性存储所有依赖,register方法注册依赖,resolve方法实现依赖注入,在之后可以模仿Angular用register注册几个模块,Angular的依赖注入服务$inject就是采取类似的思路完成依赖注入,先对函数使用toString()方法,之后通过正则匹配获得函数的输入参数,再加入依赖。
基础拓展指令
Angularjs通过ng-directives拓展了HTML。下面介绍了一些常用的directives。
ng-app:定义一个AngularJS应用程序,一般绑定在html标签下。当然也可以在个别标签下绑定。范例:<html ng-app> <div ng-app>。
ng-controller:指定特定控制器控制一个AngularJS应用程序,位于ng-app下,一般为应用下的自功能。范例:<body ng-controller=”MainCtrl”>。控制器端,app.controller ('MainCtrl', function($scope){…})。
ng-init: 在视图中初始化变量,范例:<div ng-init="book=[…]">;可以同时初始化多个变量,引号内用分号隔开即可。通常使用时,在控制器内完成,不推荐使用ng-init初始化。
ng-bind:把变量绑定到视图中。范例:<span ng-bind="book"></span>。
ng-model:定义模型数据,绑定输入域值到模型数据,Angular支持数据双向绑定,可以轻松实现数据实时更新。范例:<input type="search" ng-model="criterial">
ng-repeat:遍历集合中的元素,用来迭代DOM元素。范例:<li ng-repeat="book in books"> {{book.name}}</li>. 使用过滤器可以实现过滤文本,改变格式,甚至实现搜索功能,filter:criteria | orderBy。利用ng-repeat结合tr和td可以方便地绘制表格。
ng-include:引入本地或跨域html文件,实现组件化的效果。
还有一些ng-directives会根据条件真假决定是否是否展示,如ng-show, ng-if, ng-invalid等。其中ng-show和ng-if后有$odd和$even辅助条件判断(ng-repeat中)。
还有ng-click ng-href ng-show ng-hide等。更多请参考文档。
常用服务
$scope:是带有属性和方法的对象,是控制器后台和前端模型数据的粘合剂。可以通过它定义数据,绑定元素等。在定义控制器时,可以作为输入参数传入,使得视图可以获取控制器属性。在大型项目中,$scope(作用域)往往不止一个,在使用时要注意区别开。所有应用都有一个$rootScope,可以在同一ng-app下的所有控制器中使用,是各个scope间的桥梁。
$watch:每次绑定一些东西(如ng-model)到UI时,就会向$watch队列插入一条$watch,它可以检测model里有变化的东西。需要注意的是,通过$scope定义的模型在绑定前不会加入$watch,且对象内的属性和数组内的元素也会作为一个个体添加如$watch队列中。$watch可以手动绑定。$scope.$watch(”xxx”, function(oldvalue,newvalue){},true/false)
$digest:Angular拓展了浏览器等待用户交互的时间循环,生成一个称为Angular context的执行环境。在浏览器接收到可以进入Angular context的事件时,$digest将会遍历$watch,检查值的变化,至少一个$watch更新后,循环就会再次触发。$digest循环后,DOM相应发生变化。1个事件会触发1个$digest循环。
$apply:决定事件是否能进入Angular context。Angular会自动封装事件到一个$apply调用。因此jQuery没有调用$apply时,$digest循环不会执行。可以通过scope.$apply()强制一次$digest循环。
$q:提供了广义的异步回调机制,$http即在此基础上构建。$q有四种方法,all([p1, p2])方法合并多个promise为1个,defer()方法返回一个defer对象,reject(data)触发后链的链式回调,用在p.then().then()的链式环境下。when()方法用来将数据包装成promise对象。defer()方法返回一个defer对象,promise属性是一个promise对象,resolve和reject方法分别触发成功和失败回调。
$log:向终端打印一些信息,error(), info(), warn(), log()方法分别打印不同级别的信息。
$cacheFactory:简单封装了一个缓存机制,调用时需要id和配置项如capacity。缓存实例有info(), put(k, v), get(k), remove(k), removeAll(), destroy()等方法。
$resource:Angular封装了一个更面向RESTful的模块代替$http使用,通过$resource的配置对象可以轻松实现CRUD操作。
Angular 2
Angular的开发团队在2015年7月推出Angular 2.0版本。对比1.x版本,Angular的2.0版本改动很大。2.0版本完全由Atscript书写,完全支持最新的ES6特性。AtScript改进自Typescript,后者由微软提出于2012年,简单来看是ES5+ES6+Type,在完全兼容Javascript的同时,提出了弱类型等更像传统编程语言的特性(又是一个新坑,日后再学)。目前(2016/7)官网中并无Javascript版的2.0介绍。同时,一些诸如scope和controller的传统概念也被完全删除。组件化和面向对象成了2.0版本的最大特点。
组件化
如上文所说,controller和$scope等概念被替代成组件和命令。控制器都由模板的方式定义为类的样式,如在下文的代码中,将组件(component)绑定到<angularComponent>标签上,所有使用组件都需经bootstrap挂载,且被页面导入(imported):
//<reference path="typeings.tsd.d.ts" />
import {Component, View, bootstrap} from 'angular2/angular2';
//Annotation section
@Component({
selector: 'angularComponent',
templateUrl: '/list.html’,
directives: 'importedComponent’
})
@View({
templateUrl: 'component.html'
})
class angularComponent{
constructor(){
//code
}
}
bootstrap(angularComponent);
注意:上文应保存为.ts文件。
Angular 2.0采用ES6自带的模块特性进行模块管理,并保证全局域安全。定义组件时(Angular 1.x中称为module)中通过import from的形式引入依赖,并通过Component注解完成控制器注册。而控制器本身是通过export class xxxComponent{}的形式定义的。在组件的构造函数中用输入参数的形式完成依赖注入。
拓展命令
拓展命令的用法也做了较大改动。ng-app和ng-controller已经结合在模块的定义中。ng-click等事件删除前缀ng-,用 () 包裹,交由component方法处理。ng-href, ng-hide等有HTML5标签对应的命令删去前缀ng-,用 [] 包裹。特别地,在路由中,a标签的路径已经不需要 # 。ng-if和ng-for等控制命令删去短划线采用驼峰命名,前方加星号 * 。ng-model双向绑定数据使用[(ngModel)]。
{{}}仍起着单向绑定的作用,过滤器使用管道pipe方法替代,ngFor中的变量用let声明。另外,过滤器中的filter和orderBy被删除,需要自行实现,limitTo改为slice。
总体来说,Angular 2.0的出现也是顺应了时代的步伐,减少了繁冗的API,和对前端页面元素的过多装饰,改为更适合开发的模块化封装,通过修饰器约束组件的特性。同时保留了数据双向绑定等特点。无论如何,对于1.x的使用者来说,都要花上不少时间去适应全新的一切。更多的改变可以参考官网的对比。
更多
Q 使用Angular JS和jQuery可以兼容吗?如何做到?
A. Angular JS采用的MVVM的架构和jQuery的思路并不十分兼容,建议使用前者,养成不用后者的习惯。
Angular JS 1.x版本有着较丰富的参考资料,官网有API reference和demo分析,w3school的教程也是不错的学习资料。另外还有一些博客和gitbook可供参考。Angular 2.0版本较新,Angular 2.0版本的内容主要参考自DZone的一篇文章,同时2.0版本有了新的官网。
Vue.js
Vue是与React.js和Angular JS类似的一套构建用户界面(以单页面应用为主)的渐进式框架,比较轻量级,易于入门和动手开发。同时,也可以很容易和其他库和项目进行整合(如vue-loader)。Vue的设计目标是通过尽可能简单且易于使用的API来实现响应式数据绑定和视图组件组合。
Vue有自己的官方网站和一个很不错的中文译版。除了本身的库(star数已有41k)以外,面向复杂路由功能和复杂组件状态管理,开发组还额外提供了vue-router(star数4k)和vuex(star数5k)方便开发者管理。
第一印象
Vue在起步上不需要复杂操作,只需要引入vue.js的源文件(下载到本地或是从CDN处获取)即可。Vue在API风格上和React,Angular甚至backbone都有相似之处。这里有官方所做的对比。下面是一个最简单的使用Vue.js渲染DOM的例子。
<div id="app">
{{ message }}
</div>
var app = new Vue({
el: '#app',
data: {
message: 'Hello Vue!'
}
})
其中涉及到的vue的使用方式,若是接触过React,Angular,backbone的会很容易理解。再复杂点如下,可以结合命令实现条件、循环、数据绑定等
<div id="app">
<p v-if="seen">Now you see me</p>
<ol>
<li v-for="todo in todos">
{{ todo.text }}
</li>
</ol>
</div>
var app3 = new Vue({
el: '#app',
data: {
seen: true,
todos: [
{ text: 'Learn JavaScript' },
{ text: 'Learn Vue' },
{ text: 'Build something awesome' }
}
})
在上面的例子中,数据流向都是从上至下的,通过v-on指令可以让用户和应用进行互动,将用户输入的数据由下至上传递。
同时,组件系统也是Vue.js一个重要概念。它将前端界面抽象成独立可复用的各个小组件来构建大型应用。并通过props以及emit/on来实现组件间的信息沟通。组件内通过template定义渲染内容,组件间支持嵌套和组合。
基础
- Vue.js的应用都是通过
new Vue({})的形式创建Vue根实例的方式启动的。也可以通过var MyComponent = Vue.extend({})的形式创建自定义组件全局使用。 - 每个Vue实例会代理其
data域内所有属性,实例创建后添加的新属性将不会触发视图更新,除data域外,还有些特殊属性和方法有前缀$作为区分,见附录 - Vue实例在被创建后有自己的生命周期,并在周期变化时调用一些生命周期钩子。例如
created,mounted,updated,destroyed。该图做了细致的说明。
使用
模板
Vue.js使用了基于HTML的模版语法,允许开发者声明式地将DOM绑定至底层Vue实例的数据。在底层实现上,Vue将模板编译成虚拟DOM渲染函数。结合响应系统,在应用状态改变时,Vue会计算出重新渲染组件的最小代价并应用到DOM操作上。
如果你熟悉虚拟DOM和JSX语法,也可以通过直接写render函数替代模板的效果。
文本
数据绑定最常见的形式就是使用双大括号的语法进行文本插值。绑定的数据对象改变时,插值的内容也会实时更新。通过使用v-once指令,你还能执行一次性地插值。
如果需要纯HTML内容,可以使用v-html指令。但是不建议这么做,因为会导致难易防御XSS攻击。绑定HTML属性时需要使用v-bind指令,该指令可以简写如下:
<div :id="dynamicId"></div>在模板插值中,Vue.js还提供了完全的JavaScript表达式支持。
指令
指令(Directives)是带有v-前缀的特殊属性。除了v-for,指令属性的值预期是单一JavaScript表达式。一些指令能接受一个“参数”,在指令后以冒号指明。修饰符是以半角句号指明的特殊后缀,用于指出一个指定应该以特殊方式绑定,常用在绑定事件上。
缩写
v-bind可以缩写为半角冒号:,v-on可以缩写为@.
复杂属性
模板中放入太多的逻辑会让模板过重且难以维护。在这种情况下,模板不再简单和清晰,应该选用计算属性实现。
计算属性
可以像绑定普通属性一样在模板中绑定计算属性。在依赖属性改变时,计算属性也会跟着改变,声明式地创建这种依赖关系是易于测试和理解的。
var vm = new Vue({
el: '#example',
data: {
message: 'Hello'
},
computed: {
// a computed getter
reversedMessage: function () {
// `this` points to the vm instance
return this.message.split('').reverse().join('')
}
}
})
需要注意的是,计算属性会缓存数据,只有在它的相关依赖发生改变时才会重新取值。因此,当依赖属性并非响应式时,计算属性将不会更新,如Date.now()。
在必要时你还可以提供一个 setter,提供修改计算属性时,依赖属性的更新。
Watcher
Watcher完成的功能和计算属性类似。但是它可以作为一种更通用的方法,来相应数据的变化。这在想要相应数据变化,执行异步操作或开销较大的操作时,是很有用的。watch属性接受oldVal和newVal两个参数。
样式
数据绑定一个常见需求是操作元素的class列表和它的内联样式。我们可以用v-bind处理它们,为了减少字符串拼接,Vue.js提供了一些特供的特性。
Class
class属性接受一个对象或数组,表示绑定到之上的类名列表。甚至可以直接绑定data域内的一个对象。最佳实践是绑定到对象的计算属性。
内联样式
v-bind:style的使用方法类似上面,接受一个Javascript对象或数组。最佳实践是使用计算属性表示。
Transition
在插入、更新或者移除DOM时,Vue.js提供特色的过渡效果。使用<transition>标签包裹,结合v-if和v-show以及特殊css类名,可以实现元素的展现和消失。再结合效果库,如Animate.css或Velocity.js,可以实现酷炫的效果。不建议同时使用transition和animation。
多元素渐变时,可以在<transition>标签中指定mode属性优化渐变效果。Vue.js的<transition-group>可以专门用来处理列表的过渡效果,需要注意的是,使用transition-group时,元素需要不能是inline,更多内容见附录。
Vue.js在元素出现和消失时,会触发enter,leave等钩子函数。搭配tween.js和color.js等可以实现数值的渐变效果。
更详细的讲解见过渡一节。
流程控制
v-if/f-else
如字面意思,后跟表达式执行if功能。也可以用v-else添加一个“else”块。在和<template>标签合用时,可以包装一组标签。
V2.1.0后,新增了v-else-if。用做else-if块。
v-show
等同于v-if,不同的是,v-show的元素会始终渲染并保持在DOM中。v-show是简单的切换元素的CSS属性display。而v-if是真实的条件渲染,在条件变化时进行局部编译并缓存起来。
一般来说,v-if有更高的切换消耗,而v-show有更高的初始渲染消耗
注意,v-show不支持使用在<template>中。
v-for
v-for指令根据一组数组的选项列表进行渲染,需要item in items形式的特殊语法,items是源数据数组并且item是数组元素迭代的别名。也可以使用of代替in。v-for除了循环数组也可以循环对象,如下:
<div v-for="(value, key, index) in object">
{{ index }}. {{ key }} : {{ value }}
</div>
为了便于简单的循环,可以使用类似于n in 10这样的用法,重复多次模板。v-for也有<template>的用法。为了确保在特定索引下显示已被渲染过的每个元素,可以为元素指定key属性。
另外,需要特别声明的是,由于Javascript的限制,Vue不能检测对数组以下两种情况的改动:
- 当你利用索引直接设置一个项时,例如:
vm.items[indexOfItem] = newValue - 当你修改数组的长度时,例如:
vm.items.length = newLength
响应
数据驱动的重要一环是用户输入和响应。
监听事件
使用v-on监听DOM事件来触发一些JavaScript代码。通常情况下,把事件处理逻辑下载方法中,让v-on接收一个方法名或内联JavaScript语句。
<div id="example-2">
<!-- `greet` 是在下面定义的方法名 -->
<button v-on:click="greet">Greet</button>
</div>
在使用内联语句时,可以将原生DOM事件——特殊变量$event作为输入参数传给方法。
事件处理器支持修饰符,如.stop, .prevent, .capture, .self, .once作为语法糖。按键事件keyup还支持按键修饰符,如.enter, .delete, .esc, .space, .up, .13等。可以全局通过Vue.config.keyCodes.f1 = 112的形式设置自定义按键修饰符。.ctrl, .alt, .shift, .meta四个修饰符用来配合其他鼠标和键盘事件开启监听。
除了原生事件,在自定义组件后,父组件可以监听子组件上的自定义事件。
表单控件
v-model常用在在表单控件元素上创建双向数据绑定。它会根据控件类型自动选取正确的方法来更新元素。但它实际上只是语法糖。它负责监听用户的输入事件以更新数据,并特别处理一些极端的例子。在有特殊需要时,可以自己用v-on和v-bind实现v-model。
单选框,多选框。单选列表,多选列表等可以简单使用v-model即可,而不必自己写处理函数。复选框和多选列表的各元素共用一个v-model数组。
v-model支持修饰符.lazy, .number, .trim等。
组件
组件是Vue最关键的一个特性,同时也是最灵活最有内容的特性。组件可以扩展HTML元素,封装可重用的代码。在较高层面上,组件是自定义元素。不过,有些情况下,组件也可以是原生HTML元素的形式,以is特性扩展。
使用
通过Vue.component('my-component', {})的形式注册。对于自定义标签名,Vue建议遵循小写且包含短杠的规则。
有时不必在全局注册每个组件。通过使用components选项注册,可以使组件仅在另一个实例或组件的作用域中可用。
var Child = {
template: 'A custom component!'
}
new Vue({
// ...
components: {
// <my-component> 将只在父模板可用
'my-component': Child
}
})
当使用DOM作为模版时, 会受到HTML的一些限制,因为Vue只有在浏览器解析和标准化HTML后才能获取模版内容。变通的方案是使用特殊的 is 属性。同时,data域必须为函数,因为Vue组件可能被利用多次,使用对象定义data域会导致污染。
组件间协同工作必然需要相互通信:父组件要给子组件传递数据,子组件需要将它内部发生的事情告知给父组件。在Vue.js中,父子组件的关系可以总结为 props down, events up。父组件通过props向下传递数据给子组件,子组件通过events给父组件发送消息。
Prop
组件实例的作用域是孤立的。这意味着不能并且不应该在子组件的模板内直接引用父组件的数据。可以使用 props 把数据传给子组件。此时,子组件需要显式地用 props 选项声明prop。
初学者常犯的一个错误是使用字面量语法传递数值,如:
<comp some-prop="1"></comp>如果想传递一个实际的JavaScript数字,需要使用v-bind,从而让它的值被当作JavaScript表达式计算。
<comp v-bind:some-prop="1"></comp>同时还要注意,prop 是单向绑定的:当父组件的属性变化时,将传导给子组件,但是不会反过来。另外,每次父组件更新时,子组件的所有 prop 都会更新为最新值。这意味着
- prop作为初始值传入,子组件之后只是将它的初始值作为本地数据的初始值使用
- 确保prop不会被更改(用在计算属性中)
当prop属性为对象时,可以包含对prop的验证要求。
自定义事件
每个Vue实例都实现了事件接口(Events interface),从而都能使用$on监听事件和使用$emit触发事件。监听自定义事件的方法和原生事件一致。
在非父子通信时,通常可以使用一个空的Vue实例作为中央时间总线。如下:
var bus = new Vue()
// 触发组件 A 中的事件
bus.$emit('id-selected', 1)
// 在组件 B 创建的钩子中监听事件
bus.$on('id-selected', function (id) {
// ...
})
在更复杂的场景下,建议使用vuex管理状态。
内容分发
使用组件时,通过slot分发内容,使用特殊的<slot>元素作为原始内容的插槽。
除非子组件模板包含至少一个<slot>插口,否则父组件的内容将会被丢弃。当子组件模板只有一个没有属性的slot时,父组件整个内容片段将插入到slot所在的DOM位置,并替换掉slot标签本身。
<slot>元素可以用一个特殊的属性name来配置如何分发内容。多个slot可以有不同的名字。具名slot将匹配内容片段中有对应slot特性的元素。在父组件中,通过为标签指定slot属性进行一一匹配。
作用域插槽通过在子组件的slot中指定text属性,将子组件prop传递给父级,在父组件具有scope属性的<template>中使用。详见作用域插槽。
动态组件
多个组件可以使用同一个挂载点,然后动态地在它们之间切换。最佳实践是,使用保留的<component>元素,动态地绑定到它的is特性。如下:
var vm = new Vue({
el: '#example',
data: {
currentView: 'home'
},
components: {
home: { /* ... */ },
posts: { /* ... */ },
archive: { /* ... */ }
}
})
<component v-bind:is="currentView">
</component>当组件全局定义时,甚至可以指定在currentView后。
如果把切换出去的组件保留在内存中,可以保留它的状态或避免重新渲染。为此可以添加一个<keep-alive>标签在<component>外。
注意事项
- 编写组件时,需要设计好
Props,Events,Slots,三项都不可少。 - 组件命名时,可以使用各种风格,但在HTML模板中,请使用kebab-case形式
- 如果子组件有
inline-template特性,组件将把它的内容当作它的模板,而不是把它当作分发内容。这让模板更灵活。但是这也让作用域变得难以理解,最佳实践是使用.vue文件中的template元素。 - 另一种定义模板的方法是,使用
text/x-template类型,并指定一个id。 v-once在大量静态内容的网页中能加快Vue渲染HTML的速度。
更多
在自定义指令和Mixin上,因为未做实践,这里不做介绍,可以参考教程上的说明。vuex和vue-router也是如此。
生产环境部署中,vue-loader是很方便的利用webpack自动打包.vue文件,同时支持使用pug模板引擎,ES2015语法,Sass等CSS预处理器。岂不美哉。
附录
内置组件
component
提供一个通过is属性指定具体渲染组件的组件占位符。通过is属性指定组件名或组件属性或组件构造器,inline-template属性指定component内的内容是否为模板(这么做会混淆作用域,并非最佳实践)。component组件通常用来构建动态组件(因为is属性完全可以作为props由父组件传入)。
transition
过渡是Vue提供的很有特色的功能(虽然强大的渐变效果要借助第三方库)。与之相呼应的是enter,leave,enter-active,leave-active,appear,appear-active这些css预置类名。类名前缀由name属性指定,或者通过类名后+"class"作为<transition>属性名手动指定。另外,mode属性定义多个过渡同时出现的先后关系,有out-in和in-out两种。css(boolean)属性决定是否关联css过渡类,type属性指定过渡为transition或是animation。
Vue维护transition的一些内部事件,包括before-enter,enter,after-enter等,可用于js钩子函数监听。<transition>本身不对应DOM元素,只是将需要过渡效果的内容包裹在里面。
transition-group
与<transition>不同,<transition-group>元素渲染多个元素或组件的过渡效果,且对应一个真实的DOM元素(默认为span,可以通过tag属性修改)。它内部支持CSS transform过渡移动。过渡效果通过name属性或move-class属性对应CSS自定义类。
需要注意的几点,1)<transition-group>的子节点必须有独立的key;2)子节点必须为inline-block或是flex,FLIP动画效果才有效果。
slot
用于父组件进行内容分发。内容分发后自身会被替换掉。name属性用于对应父组件的slot属性元素里的内容。
实例配置选项
在通过new Vue()或Vue.extend创建Vue实例时,可以指定一系列初始化配置选项。
el string | HTMLElement
Vue实例挂载的DOM元素。可以是CSS选择器或是HTMLElement实例。当该选项未指定时需要通过vm.$mount()手动开启。
template string
使用一个字符串作为实例的渲染模板。除非模板有slot分发,模板内容将会替换挂载元素内容的所有内容。如果值以#开始,将使用匹配元素的innerHTML作为模板。
render Function
template属性的替代方案,render函数接受一个createElement函数作为第一个参数创建VNode。createElement函数接受三个参数,第一个参数表示绑定DOM元素,可以为String或Object或Function,第二个参数为修饰HTML标签的数据对象,第三个对象表示子节点,可以是String或Array类型。createElement内容较多,可以参见Render函数一节。
如果组件为函数组件,则还可以接受context参数创建上下文。
data Object | Function(组件定义中)
Vue实例的数据对象。Vue将会递归将data的属性转换为getter/setter,从而让data的属性能够响应数据变化,不推荐观察拥有状态行为的对象。实例创建之后,可以通过vm.$data访问原始数据对象。注意,为避免冲突,以_或$开头的属性不会被Vue实例代理。
props Array
props用来接收来自于父组件的数据。props可以是简单的数组,或者使用对象作为替代,使用对象时允许配置高级选项,如类型检测(type)、自定义校验(validator)和设置默认值(default)等。
propsData { [string] : any }
用于创建实例时传递初始化的props,一般用于测试。
methods { [string]: Function }
methods属性和data属性类似,会混入到Vue实例当中,可以直接通过实例来访问这些方法。方法中的this绑定该Vue实例。因此不能使用箭头函数定义method函数。
computed { [string]: Function | { get: Function, set: Function } }
用于定义计算属性,计算属性将混入在Vue实例的属性中,同时绑定getter和setter函数。为了保证效率,计算属性结果会被缓存,当依赖属性更新时重新计算。最佳实践时用于表示data属性的简单计算得到时。在计算过程复杂或耗时时,选择watch选项。
watch { [string]: Function | { get: Function, set: Function } }
键为观察的表达式,值为对应的回调函数。回调函数可以是方法名或是匿名函数,它接受原值和新值作为两个输入参数。同样,不应使用箭头函数定义watcher函数。
实例常用属性
Vue实例创建后,默认的实例属性来自创建实例时的data属性。需要访问实例本身特性时统一在特性前加上$符号。根据官网教程的介绍,惯例使用vm作为创建Vue实例的变量名,下面也是如此。
vm.$data Object
Vue实例储存的数据对象,Vue通过setter和getter的形式代理对data属性的访问。通过类似vm.foo的形式访问。
vm.$el HTMLElement
返回Vue实例使用的根DOM元素。类型为HTMLElement。
vm.$root Vue instance
当前组件树的根Vue实例或自己。
vm.$slots { [name: string]: ?Array
用来访问当前组件中被slot分发的内容,具名slot的内容可以通过vm.$slots.foo的方式来访问,default属性包括了所有未具名slot中的节点内容。2.1.0版本后新增了$scopedSlots访问作用域slot。
vm.$refs Object
类似于React中的用法,访问所有在HTML中声明ref属性的DOM节点。当ref属性声明在组件上时,返回该组件实例。
vm.$on(event, callback)
监听当前实例上的自定义事件。事件可以由vm.$emit触发。回调函数会接收所有传入事件触发函数的额外参数。此外,vm.$once完成同样的效果,但是只监听一次。
vm.$emit(event. [...args])
触发当前实例上的事件。附加参数都会传给监听器回调。
此外,vm.$options返回创建实例时输入的初始化选项;vm.$parent返回当前实例的父实例,vm.$children返回当前实例的直接子组件。vm.$off移除事件监听。
生命周期钩子
在Vue实例的生命周期里,会触发一些钩子函数。函数中的this自动绑定到该实例。
beforeCreate
在实例初始化,数据观测前调用
created
实例创建完成后调用,测试数据观测,属性方法运算,watch/event回调都已经完成。但是元素尚未渲染和挂载,$el属性不可见。此时对所做的DOM操作无效。
beforeMounte
在挂载前调用,render函数首次被调用。
mounted
el被新创建的vm.$el替换,并挂载到实例上去之后调用该钩子函数。
beforeUpdate
数据更新发生时,虚拟DOM重新渲染和patch之前。
updated
虚拟DOM重新渲染和patch之后。
此外,还有activated,deactivated用在keep-alive组件切换内部组件时;beforeDestroy,destroyed用在实例销毁时。

MangoDB
MangoDB是node开发中经常用的数据库。这里做简单介绍。
简介
MangoDB是一个基于分布式文件存储的NoSQL数据库,介于关系数据库和非关系数据库间。NoSQL相比关系数据库而言,更适合与海量的网络应用数据,而SQL则更适合商业事务的存储与处理。基于NoSQL的MangoDB由C++编写,它将数据存储成文档,数据结构由键值对组成,类似于JSON对象。
MangoDB的安装部署十分简单。去官网下载预编译包安装后,在根目录下创建数据目录即可。
基本单位
MangoDB中保留了database和索引的概念,将表视作集合,将数据记录行视作文档,将数据字段视作域,联表替换成文档嵌入,会自动将_id字段设置为主键。
在MangoDB自身提供的shell下,show dbs可以查看所有已有的数据库。db可以查看当前的数据库对象,使用use xxx可以切换数据库。数据库通过名字来标识,admin, local, config是保留的特殊数据库。
文档是一个键值对,文档不需要设置相同的字段,且相同字段不要求相同数据类型。同时文档中的值甚至可以是其他的富数据类型。
集合等同于RDBMS中的表,存在于数据库中,没有固定结构。当第一个文档插入时,集合就会被创建。Capped collection是固定大小的集合,是高性能的自动维护对象插入顺序的集合。需要显示的创建。
数据库的信息储存在{dbname}.system这个系统空间中,它的各字段包含着多种系统信息。其中个别字段支持修改或删除。
连接/创建/删除数据库
在shell(支持JavaScript语法)下,通过命令mongodb://localhost连接数据库,若有用户名和密码,须写成mongodb://username:password@hostname/dbname的形式。
使用use命令可以创建或切换到指定数据库。使用db.dropDatabase()删除当前数据库,使用db.createCollection()创建集合。db.collection.drop()删除集合。
CRUD操作
db.COLLECTION_NAME.insert(document)插入文档,文档格式和JSON基本一样,也可以先将文档存储在变量中。若指定的集合不在数据库中,MongoDB会自动创建该集合并插入。insert()方法可以认为是不指定_id字段的save()方法。
db.COLLECTION_NAME.update(QUERY, UPDATE,{upsert: BOOL, multi: BOOL, writeConcern: …}). query是查询条件, update是update内容和更新操作符。常用操作符有$set $unset $inc $rename $setOnUpdate $(query)等. upsert意义是如果不存在update的记录是否插入新纪录,multi意为若找到多条是否更新多条。save方法则通过传入一个带有_id的文档,替换原id的文档。
db.COLLECTION_NAME.remove(QUERY, JUST_ONE),第一个参数指定查询条件,第二个参数选择是否只删除一条。
db.COLLECTION_NAME.find()以非结构化方式显示所有文档。pretty()方法以格式化方式显示所有文档。find()方法可以接受条件作为where子句。同样用{}方式表示大小关系,有$lt $lte $gt $gte $ne操作符,这些操作符可以并列书写,如{likes: {$lt: 200, $gt: 100}}。用逗号隔开的键值表示并列的AND条件,用$or表示OR条件,以$or:[{}{}]的方式使用。同时$type操作符可以用于筛选特定类型的字段。
limit()方法同样可以跟在find()后面,类似于SQL语句中的LIMIT。skip()方法用于跳过find(n)方法得到的前n条文档。sort()类似于ORDER BY,通过{KEY: 1/-1}来控制特定字段的升降序。
索引与聚合
db.COLLECTION_NAME.ensureIndex({KEY: 1/-1}. {background: true/false})用来创建索引,提高搜索效率。KEY的位置可以指定多个字段,创建复合索引。第二个参数指定是否后台执行。
集合还有aggergate(middleware)方法用于聚合,类似SQL的聚合函数。接受若干个中间件作为输入参数。中间件可以有project,match,limit,skip,unwind,group,sort,geoNear。分别修改输入文档的结构,过滤数据,跳过指定数目文档,拆分数组类型字段,文档分组,排序输出,按地理位置排序。$group类似SQL中的group by,需要指定_id和输出字段名。聚合表达式有$sum, $avg, $min, $max, $first, $last, $push, $addToSet.
其他
可以通过应用ObjectId的方式嵌入文档实现关系。当引用在不同的数据库、集合、文档时,通过DBRefs引用外部内容,有操作符$ref $id $db 可以使用。
查询的explain()和hint()方法分别用来提供查询信息和强迫MongoDB使用特定索引查询。
复制:在使用mongod启动时指定--replSet参数设置副本集。在客户端通过rs.add加入。
分片:通过Shard, Config Server, Query Router完成分割数据的功能,具体略
备份:使用mongodump工具指定要备份的数据库,使用mongorestore数据恢复
Socket.io
简介
socket.io是为网络应用提供跨平台实时通信的javascript库。它旨在建立客户端与服务器端的持久性连接,并模糊底层传输机制的实现细节。socket.io主要采用了HTML5中的WebSocket技术(注意是HTML5,并非是HTTP协议的新技术),同时,该库也支持一些降级功能使用在不支持WebSocket的环境下,如AJAX long polling, AJAX multipart streaming, JSONP Polling等实现方式。
WebSocket
在WebSocket出现之前,有着其他和建立socket连接效果类似的做法。如AJAX轮询,浏览器每隔数秒向服务器发起请求,询问是否有新信息出现。Long polling也是类似,不过采取的阻塞模式。服务器端若没有新信息,就没有Response返回到客户端。由于HTTP协议的被动性,前者要求服务器很快的处理速度,后者要求服务器支持高并发的能力。
WebSocket是HTML5出的新协议,作为HTTP1.1版本的补充。相比非持久的HTTP协议来说,WebSocket是一个持久化的协议。HTTP的生命周期由Request发起,在Response后结束。HTTP1.1中,keep-alive特性可以在一个HTTP连接中,发送多个Request,接受多个Response,但是Response被动返回的特点没有改变。
WebSocket协议在握手时借用的HTTP协议, Connection和Upgrade字段分别为Upgrade和websocket,意为告诉服务器当前的连接要使用websocket协议。客户端发送Sec-WebSocket-Key,Sec-WebSocket-Protocol,Sec-WebSocket-Version分别为一个验证随机字符串,服务名和WebSocket协议版本,服务器返回正确的Sec-WebSocket-Accept和Sec-WebSocket-Protocol后,握手成功。接下来按照WebSocket的协议进行通信。关于WebSocket协议的细节,这里从略。
socket.io中主要采取WebSocket完成持久性连接,但是当浏览器不支持WebSocket协议时,也只能采取上面提到的一些替代方法。
安装与使用
使用命令npm install --save socket.io或是写在package.json文件中直接通过npm install安装。官方例子中,安装前需要预装express。
安装完成后,在服务器端通过require(socket.io).listen(server)引入,之后io.on(connection, function(socket){…})即可对socket进行操作。on方法可以监听一个emit释放的事件,第一个参数为事件名,第二个参数为一个处理数据的函数。该函数接受两个参数,第一个为接受的数据,第二个为要返回的函数。socket.io默认支持connect,message,disconnect三个事件,用户也可以定义自己的事件。服务器端完整代码如下:
/* server.js */
var app = require('express')()
, server = require('http').createServer(app)
, io = require('socket.io').listen(server);
server.listen(80);
app.get('/', function (req, res) {
res.sendfile(__dirname + '/index.html');
});
io.sockets.on('connection', function (socket) {
socket.emit('news', { hello: 'world' });
socket.on('my other event', function (data) {
console.log(data);
});
}); 在浏览器端,通过引入 即可使用浏览器端的socket.io。通过io()启动客户端,默认与localhost建立连接。接下来就可以通过on和emit方法和服务器端进行沟通了。emit方法用来触发一个事件,第一个参数为事件名,第二个参数为发送的数据,第三个参数为回调函数。值得注意的是,服务器端和客户端都有emit和on方法。客户端完整代码如下:
<script src="/socket.io/socket.io.js"></script>
<script>
var socket = io.connect('http://localhost');
socket.on('news', function (data) {
console.log(data);
socket.emit('my other event', { my: 'data' });
});
</script>
在官方样例中,还展示了socket.io的广播功能,socket.emit()向该连接的客户端广播,socket.broadcast.emit()向除此客户端外的所有客户端广播,io.sockets.emit()向所有连接到服务器端的客户端广播。
部分API
TODO
Jade
简介
Jade实际上属于模板引擎的一种,模板引擎可以便于HTML文档的书写。Jade受Haml简写法的影响,它是用JS实现的,可以供Node.js使用,具有高度可读性。Jade通过行首的标签和缩进控制文档结构。通过过滤器可以书写less、markdown、coffee-script等内容。同时,jade也有其他语言的实现,包括php,scala,ruby,java等,可以实现前后端渲染的统一。
通过npm install jade下载jade,指定全局选项-g后,可以使用jade命令。
语法
Jade的语法和markdown也有许类似。
Jade使用doctype html, xml, transitional, mobile, basic, 1.1...代替最外围的标签结构,默认为html5,在doctype下书写html开始文档。
Jade中,将标签放在行首,它能自动识别自闭标签如<input>。标签后加空格,可以添加标签文本,嵌套标签时,换行使用缩进即可。当标签内容很多时,在标签后添加句点. 配合缩进或者在每段前加入 | 将下面的文本转为plain text类型。
Jade中使用()分割属性,()内的内容和html标签一致,可以用空格或逗号隔开。注释使用//书写,在//后添加短横线-,可以将注释视作jade注释。同时支持IE版本注释。
使用类似于css选择器的方法,用#和句点标注id和class,在标签后紧跟不带空格,如果没有标签名,默认为div标签。
使用# {}使用之前用var声明的变量,变量中的特殊字符会被转义,使用!代替#表示不转义。以短横线-开始非缓冲代码,如for循环结构。用紧跟标签的=表示缓冲代码,会默认转义内容,!=表示不转义。循环结构用each VAL[,KEY] in OB表示。选择结构用case when表示类似于switch,可以多个when执行同一语句块。
Jade允许使用extends结合block关键字预定义一个模板文件给其他模板调用,实现模板的集成。includes允许我们插入另一个jade文件到当前文件中,从而实现多重继承,除了.jade文件还可以引用.html甚至.css .js以及纯文本文件等。可以通过过滤器引入其他模板格式的模板。
通过mixin name(args)可以定义代码片段,通过+name(args)的形式引用,类似于函数的用法。Mixin中还支持attribute,可以在+name(args)后跟其他的属性。同时在mixin中指定了block时,可以使用include那样的块。
使用过滤器如:markdown可以导入其他格式的模板。下面是一个使用jade模板引擎的样例:
doctype html
html(lang="en")
head
- var name = 'Jade'
title= name
meta(charset="utf-8")
link(rel="stylesheet", type="text/css" href="/stylesheets/style.css")
body
h1 Jade - node template engine
#container.col
if name === 'Jade'
p #{name} is very cool
else
p Get on Jade
footer
p.
Jade is a terse and simplae
templating language with a
strong focus on performance
and powerful features.更多参考中文教程,还可以进行在线演示。另外,由于jade商标已被其他的商业公司注册,jade-lang现已更名为pug,官网已更换为pugjs。
D3.js
简介
D3全称Data-Driven Document,是使用javascript的实现数据可视化的函数库。它是一个颇受关注的开源项目,官网为http://d3js.org。它不仅可以完成dom元素操作,更可以在画布上完成图表的绘制。
HTML中提供两种标签SVG和Canvas来完成这个功能。其中SVG使用XML格式定义图形,绘制矢量图;Canvas是H5提出的新标签,用JS绘图,绘制的是位图。D3的许多图形生成器都是只支持SVG的。因此下面先对SVG做简要介绍。
SVG介绍
SVG同XML格式定义二维图形和绘图程序,在改变尺寸时不会损失图像质量,是W3C的标准之一。svg可以通过embed,object或iframe标签嵌入进HTML页面中,并按照后来居上的规则渲染。下面的内容糅合自w3school和MDN的SVG教程。
坐标
SVG使用的坐标系统以左上角为原点,x轴正方向向右,y轴正方向向下。点或形状的左上角以坐标的形式定位。SVG中的长度不标注单位时表示使用相对大小,默认为用户单位。
形状与路径
SVG有许多预设的形状元素。其中常用的有<rect> <circle> <ellipse> <line> <polyline> <polygon> <path>。<rect>有x, y, width, height, rx, ry(圆角半径)等属性。<circle>有r, rx, ry三个属性,<ellipse>有rx, ry, cx , cy(圆心位置)四个属性,<line>有x1, x2, y1, y2四个属性。<polyline>将转折点系列放在points属性中,<polygon>和polyline类似,不同的是polygon路径最后一个点会返回第一个点。<path>通过d属性绘制路径。
<path>常用于绘制复杂的图形。d属性由命令和位置组成。命令由一个字母表示,大写字母表示绝对定位,小写字母表示相对定位。M [x, y]命令表示将画笔当前位置移动到(x, y),但并不画线。使用L [x, y] H x V y可以画线,后者表示水平和垂直线。Z命令表示添加一条线段到路径起点闭合路径。C [x1 y1, x2 y2, x y]绘制三次贝塞尔曲线,S [x2 y2, x y]命令延长三次贝塞尔曲线,Q [x1 y1, x y]绘制二次贝塞尔曲线,T x y延长二次贝塞尔曲线。A [rx ry x-asis-rotation large-arc-flag sweep-flag x y]绘制弧形,rx ry分别表示椭圆长短轴长度,x-axis-rotation表示椭圆旋转角度,large-arc-flag表示是否选择较长弧,sweep-flag表示选择画弧旋转方向,x y表示终点坐标。
填充与边框
SVG使用属性fill和stroke属性完成填充和描边上色,颜色命名可以已使用css颜色命名方案。fill-opacity和stroke-opacity分别控制两者的透明度。描边里,stroke-width确定描边宽度,stroke-linecap指定线段两端格式,有butt, square, round可以选择,stroke-linejoin指定线段连接处格式,有miter, round, bevel可以选择。stroke-dasharray指定虚线的空白和实线长。另外,还有fill-rule定义重叠位置上色,stroke-miterlimit定义绘制miter效果的情况,stroke-dashoffset定义虚线开始位置。另外,可以通过css修饰svg标签,同样有内联、内部定义和引入外部css文件三种方式。需要注意的是,内部定义许放在svg标签的<def>中,使用fill和stroke表示填充和描边。
<pattern>元素中,可以包含任何之前包含的基本形状。它定义了单元系统和大小位置。x和y属性定义了pattern的起始点,width和height定义了下一个box要跨过多远。patternUnits用于描述模式本身的单位系统。patternContentUnits描述了基于基本形状的单元系统。对象改变大小时,pattern对象会自适应,但是对象里面的内容不会。pattern的单位系统混合使用了userSpaceOnUse和objectBoundingBox,易混淆。详细讨论略。
文字写在<text>元素内,通过x和y属性确定位置。<tspan>用来强调文本,有x, dx, y, dy, rotate, textLength等属性,须放在<text>或<tspan>下使用。tref元素允许通过xlink:href引用已定义的文本。textPath利用xlink:href获得一个任意路径,让字体环绕路径。text-anchor属性可以改变文字的对齐方式,可以选择start, middle和end。<text中的内容可以用字体相关的属性修饰,如font-size。
渐变与变形
<linearGradient>通过绑定id为标签添加渐变效果,通过<stop>子标签设置关键位置,在其中指定offset, stop-color, stop-opacity属性。同时渐变的走向由linearGradient标签的x1, x2, y1, y2决定。径向渐变由标签<radialGradient>完成,在属性里用cx, cy, r决定渐变的范围,由fx, fy决定渐变的中心。渐变的格式可以用CSS格式定义。整个渐变定义写在defs标签内,通过fill=url(#gradient2)的形式引用。
两种渐变都有spreadMethod属性控制渐变到达终点的行为,可以为pad, reflect, repeat几种选择。同时gradientunits属性描述渐变大小和方向的单位系统。
<g>元素通过为之赋属性将属性赋给整个元素集合。元素的transform属性有许多变换方式,translate(x,y)将元素移动到x,y的位置,rotate(x)旋转x°,skewX和skewY(x)可以将矩形斜切为菱形,scale()可以以一定比例缩放元素。Matrix(a,b,c,d,e,f)可以指定通用的变形。
剪切与遮罩
clipping用来移除编出定义元素的部分内容,即剪切。masking允许使用透明度和灰度遮罩计算的的软边缘。<clipPath>通常定义在defs标签里,通过元素的clip-path属性引入,在clipPath标签中的形状最终不会绘制,它的像素只用来确定哪些像素需要呈现出来。剪切外的形状将彻底消失。利用遮罩可以将一个元素淡入淡出,同样mask标签内的形状确定了它的影响范围,但渐变性质将会反映到引入它的形状上。Mask中标签属性可以用fill-opacity和stroke-opacity指定透明度。
滤镜
SVG中有着相当丰富的滤镜。滤镜需要写在<filter>标签内,有feBlend, feColorMatrix, feComponentTransfer, feComposite, feConvolveMatrix, feDiffuseLighting, feFlood, feGaussianBlur等许多,它们有着不同的配置方式,且有的原理并不好理解。这里不做过多介绍。具体可参见W3C的filters部分介绍
其他
SVG中可以通过<font>定义一个字体,该标签中有font-face, missing-glyph, glyph等标签可以使用。在font定义完成后,在text的font-family属性中即可引入自定义字体。实际上,css3中已有了引用远程字体的@font-face。SVG中也有image元素,支持PNG, JPG和SVG图像,引入后可以对之进行SVG的一些操作。foreighObject元素用来引入任意XML。
DOM操作API
D3提供了许多可用的API,从基本的array到DOM操作再到SVG绘图十分丰富。官方API reference做了详尽的解释。
D3对DOM的操作和jquery类似,有一个全局对象d3,先选取元素再对元素做操作。由于d3的方法通常返回也是包含htmlElement的d3对象,因此支持链式调用。D3采用CSS3的选择器语法选择元素,包含标签、类名、伪类、id名、attribute([type=text])或容器(parent, child)。同时D3的选择器支持逻辑运算即AND, OR。在选取元素后,D3通过对之操作完成功能。操作包括获取、设置属性, style, properties, HTML, text等等,或是添加移除元素。D3中可以直接对选择集(selection)做操作,或是each遍历操作。
在选择元素时,d3提供了d3.select和d3.selectAll两种方法。它们都支持选择器和节点两种输入参数。后者可能会在时间监听中以d3.select(this)的形式出现。
选择集通常是元素的数组。可以通过D3的操作函数统一对选择集做操作。Selection.attr(name[ ,value])获取或修改选择集的特定属性。value为常量时,所有属性一致,value为function时,接受数据datum,索引i和this只想当前的DOM元素,函数返回值将替代源值。当value为null时,视作removeAttr。name可以为object类型。
Selection.classed(name[, value])是用来修改class属性的attr的特殊版本。name中用空格隔开或输入object可以同时设定多个classes。与上面类似,value可以为function。value为false时,等同于removeClass。只有name时,返回选择集中第一个非空元素是否有该类。
Selection.style(name[, value[, priority]])和以上类似,用来设置和获取CSS格式。name可以输入对象, value可以输入函数。没有value时,返回计算后的CSS格式。
Selection.property(name[, value])用来修改/获取attr获取不到的属性值,如text区域的value,checkbox的checked属性或__data__等。使用方式同上。
Selection.text([value])用来获取修改选择集的文本值, 使用方式同上。Selection.html([value])用来获取innerHTML。区别在于前者基于textContent,后者基于innerHTML。
Selection.append(name)在当前元素后添加一个子元素作为选择集的最后一个结果。数据将继承当前元素。同样name接受返回DOM元素的函数,此时函数可以接受datum、i和this。name为string时,将继承所在父空间的namespace。
Selection.insert(name[, before])在选择集中before选择的元素前插入元素。如果before未找到匹配,将在最后插入。before可以是选择器或返回DOM元素的函数。
Selection.remove()删除当前选择集。返回选择集本身,因此也可以链式调用。
关于数据绑定,有selection.data([values[, key]), values可以是数组或是返回数组的函数。在key未指定时,values和selection中的元素一一对应。在绑定后写入在元素的__data__ property中。函数返回update选择集。提供了enter和exit方法获取enter和exit选择集。key参数规定了values和selection元素的绑定方式,具体参见wiki。data方法不能用来清除已有的绑定数据。通过Selection.merge(name)和已知selection合并。
Selection.datum([value])设置或获取绑定数据,简化版的data方法。可以理解成上文中property方法的子集。由于没有绑定过程,因此也没有enter和exit选择集。value可以接受常量或是函数,用法类似其他使用value的方法。它还能和W3C的dataset属性互动。和data不同的是,datum绑定为元素们绑定相同的数据,且新插入的元素也会具有相同的datum。而data则是将数组中的各元素一一绑定在一个个元素上。
Selection.enter()返回enter选择集:未和data匹配的占位符。只定义在update选择集后,其后只能跟append, insert, select和call方法,用在数据较多时,通常添加元素并赋予属性值。Selection.exit()返回exit选择集:未和data匹配的节点,其后可以跟普通的操作方法,但通常使用remove()删除多余元素。两者相互对应。
注:update, enter和exit和选择集是较难理解的一部分。这些概念出现在绑定数据时,update记录更新的选择集,enter和exit分别用于两者并不等量的情况。Ourd3js中的图会起到帮助理解的作用。应用模板的介绍参见教程
Selection.filter(selector)用来过滤选择集,同上面的函数,selector除了选择符外还可以是返回DOM节点的函数,函数接受d和i两个参数,this表示当前DOM节点。
Selection.sort([comparator]),根据comparator函数排序选择集,再重新插入到文档的元素中,并返回新的选择集。排序非稳定。Selection.order()可以迅速按照order重排元素。
Selection.on(type[, listener[, capture]])用法和jquery类似,listener为函数,可以接受datum及index两个参数并使用this。其余的还有d3.event d3.mouse(container) d3.touch(container[, touches], id) d3.touches事件可以利用。通过这个方法,可以为d3创建的图表添加交互式操作。
Selection.transition([name])开启一个渐变过程,使得上面的这些操作能够有渐变效果。关于transition更多选项见API的transition部分。Selection.interrupt([name])可以立即停止一个渐变,没有name时会停止当前渐变。
最后selection.each(fucntion)和selection.call(function[, args])分别对选择集每个元素操作和调用特定函数对选择集处理。Selection.empty(), Selection.node(), Selection.size()返回选择集的一些性质。
比例尺API
比例尺常用在d3制图当中,在d3的v3.x版本中,位于scale子模块内,在v4.0版本中抽离了出来作为单独模块使用。D3中的比例尺有连续比例尺、序列比例尺、临界比例尺、分位数比例尺、量化比例尺与序数比例尺。这些比例尺都有定义域和值域分别称为domain和range。使用时指定两者的范围便可得到映射关系。而以上的比例尺则是根据定义域和值域类型区分的。
线性比例尺将连续区间映射到另一连续区间。通过d3.scale.linear()初始化,在4.0中通过scaleLinear()初始化,链式定义domain([numbers]),range([numbers])即可。linear(x)得到y,linear.invert(y)可以得到x。tick([count])设置刻度数,默认为10,tickFormat(count, [format])设置刻度格式。注意,定义域和值域都可以定义成多段,类似于分段函数。d3.max和对d3.min方法分别可以计算数组内的最大/小元素。
其他的比例尺还有identity()恒等比例尺,domain和range永远一致,且默认值为[0, 1],类似于恒等变换。pow()和log()也是两种特殊的连续比例尺,即指数和对数变换,用法与linear一致。time比例尺是v4.0中新的比例尺,是以时间为定义域的连续比例尺。
序数比例尺的定义域是离散的。类似linear(),有domain和range方法。同时还有rangePoints, rangeRoundPoints, rangeBands, rangeRoundBands这些range的替代方法修饰输出的比例尺。这些在v4.0中分别作为了独立的比例尺类型。
其余的比例尺还有quantize(),定义域是连续的,值域是离散的。根据值域等比例划分定义域,有domain, range, invert等方法。其他的比例尺还有和quantize很像的quantile以及threshold比例尺。具体见文档。V4.0中还有序列比例尺,它的range是根据插值器写死的且不可配置,利用已有的颜色插值器可以生成超酷的颜色比例尺。具体见d3-scale-chromatic。
这些比例尺都有copy方法,方便地复制给其他比例尺变量。
坐标轴API
V3.x中作为svg的一个组件,V4.0中提出为单独组件。d3.svg.axis()创建一个默认的轴,在V4.0中可以直接使用d3.axis()。定义后通过axis(selection)绑定在svg或是g元素上,通常采用.append(g).attr(transform ,translate(x,y)).call(axis)的形式使用。
axis.scale([scale])方法设置比例尺,从而将刻度与实际长度对应。axis.orient([orientation])选择坐标轴方向和刻度方向,默认为bottom。axis.tick([args])方法指定刻度属性,参数将传递给scale.tick()方法生成刻度值。axis.tickValues([values])设置/获取刻度值。axis.tickSize([inner, outer])设置内外部刻度尺寸。另外外有tickPadding, tickFormat等方法。V4.0中直接通过d3.axisTop, d3.axisRight, d3.Bottom, d3.Left设置方向
渐变API
ease()完成渐变和动画效果。在V3.x版本中主要由transition()完成渐变,ease模块添加于4.0版本。渐变通过d3.transiton([selection], [name])或者selection.transition()初始化,以后者为主。方法返回transition对象,并启动过渡。transition.duration([duration])指定过渡时间,ease([value[, args]])方法指定过渡方式,delay([dalay])方法指定延迟时间。ease方法常用的有linear, circle, elastic, bounce, cubic, exp, poly(k), sin等缓动函数。V4.0版本中,ease单独拿出来作为了一个模块,有更丰富的用法,可参加V4.0 API文档。>
transition后还可以跟attr, style, text方法做缓动变化。tween方法介绍见API文档,这里从略。transition中同样可以通过子选择集创建子过渡,也有类似于selection 的each, empty, node, size, call等方法。
注:transition在使用时和selection有很大相似之处。但实际上,两者类型不同,selection对应d3的选择集对象,transition对应d3中的渐变对象。如on方法可以跟在selection后却不能更在transition后。另外,transition可以通过selection.transtion()方法获取。
布局API & 形状API
布局API起到将数据转换为用于绘图的关键作用。它更适合那些希望有更开放设计空间而不仅是利用Highcharts或是Echarts的用户。D3的V3.x版本的layout模块里提供了12个基本布局:饼图,力导向图,弦图,树状图,集群图,捆图,打包图,直方图,分区图,堆栈图,矩阵树图,层级图。其中层级图不能直接用来使用。它们的作用是将数据转成更适合这些图展示的新的数据。V4.0中这些子类型图都独立出来作为单独模块。这些图的样子可以参见官网d3js.org。
布局API输出的是格式化后的用户数据,还需要svg的部件形状AP来画出图形。部件的各部分同样在V4.0中抽出独立。有arc, area, chord, diagonal, line, symbol等几种帮助用户轻松画出svg中复杂的<path>。
饼状图
饼图布局可以将数据转成有着起始和终结角度的弧,然后轻松地通过arc shape做出饼图。实际上可以直接通过arc shape完成这一功能。通过d3.layout.pie()完成布局初始化,之后由pie(values[, index])为饼图布局赋值。返回的每一个对象都有着value, startAngle, endAngle, padAngle, data5个属性。返回元素的排序和原数组一致。此外,pie对象还有value([accessor])方法预处理数组数据,sort([comparator])方法为数据排序,保留原index,排序函数可以接受键值对,同时可以使用d3.descending和d3.ascending。另外startAngle, endAngle和padAngle方法可以获取/设置起始,终结,填充角度值。
通过上面API得到的piedata通过弧生成器即可得到饼图各部分。d3.svg.arc()可以构造一个新的弧生成器,arc.innerRadius([radius])和arc.outerRadius([radius])及cornerRadius([radius]) padRadius([radius])分别设置内环,外环,边角半径,同样可以输入函数。startAngle(),endAngle()和padAngle()也是类似的道理。通过centroid(args)还可以得到产生弧的中心,便于插入文本描述。
力导向图
力导向图是一种互动性很强的可视化图。这种图中,节点间用连线连接,连线长度几乎相等,且不相交。节点和连线间都有里的作用,这个力是根据节点和连线运动轨迹计算的。根据里的作用来不断计算节点和连线的轨迹,最终达到能量最低的稳定态。可以看到,很适合拓扑图,实际生活关系图等多对多关系的绘制。
从上面描述可以知道,力导向图的数据由节点间的连接情况组成。同上节,需要用到layout中的force部件。force创建的布局是有状态的,所以对于给定的力导向布局,只能与单一数据集绑定。通过d3.layout.force()初始化力导向实例。有links, nodes, size, friction, strength, distance, charge, gravity, theta, alpha等参数可以定制。
links()和nodes()分别用来导入节点和链路数据,导入后的节点多了index索引,px py记录上个位置,x y记录当前位置,weight记录节点权重。导入后的链路有source和target属性标注链接关系。size([width, height])用来确定力作用域的范围,力的中心为[x/2, y/2]。若节点无x和y属性,则会被初始化为[0,x]和[0,y]的上的随机值。linkDistance([distance])设置连线长度,可以传入函数,函数接受link, i两个参数。链路约束采用的力学模型不是弹簧式的,而更像弱位置约束。可以在tick方法中修改默认力学模型。linkStrength([strength])设置链路的坚硬程度,需在[0,1]之间,可以输入函数。friction([f])方法描述节点减速的快慢,需在[0,1]之间,越靠近1,节点越快停止运动。charge([charge])描述相互作用力的大小,可以输入函数,负值表示斥力,正值表示引力,可以根据场景选择。chargeDistance()设置力的作用距离,默认为无穷。theta()方法设置算法的准确度。gravity()方法设置作用域中心对节点的吸引力,越靠近中心越小。alpha()获取/设置当前能量,从而影响收敛程度。
force.start()方法启动力导向布局的仿真,并根据alpha的值逐步收敛并最终停止。resume()方法和drag动作会重新启动force仿真。force.resume()等同于force.alpha(.1)可以重新启动一个force仿真。force.stop()终止一个仿真。force.tick()进行一步force仿真。
force.on(type, listener)注册一个监听器。force.drag()可以通过node.call()的形式调用,并允许拖拽效果,在dragstart事件中设置fixed为true还可以拖拽后固定节点。范例如下:
var drag = force.drag()
.on("dragstart",function(d,i){
d.fixed = true; // true or false
}) 弦图
弦图可以用来描述两个节点间的联系和权重程度,且两点间的联系是有向的,非对称的。弦布局同弦形和弧形协同工作。通过d3.layout.chord()或d3.chord()初始化。
chord.matrix([matrix])指定用到的数据矩阵,V4.0中使用chord([matrix])实例化生成。chord.padding([paddings])指定不同组间的填充角度,可以为函数。sortGroups()方法使用指定函数为布局设定分组排列顺序。sortSubgroups([comparator])方法设定组内各列的排列顺序,sortChords([comparator])指定弦在Z轴上的堆叠顺序。chords()方法返回通过给定参数计算过的弦对象。groups()返回计算过的分组对象。groups为对象的数组,对象有endAngle, index, startAngle, values4个属性。Chord的元素有source和target两个属性,这两个属性也是对象类型,内部都有endAngle, index, startAngle, subindex, value这几个属性。在使用layout.chord()生成弦和边缘时,分别由arc生成器和chord生成器生成形状。同样,生成的path最好包裹在<g>标签内。
在V4.0版本中,计算出的chords会交给d3.ribbon完成展示,且可以直接通过指定startAngle, endAngle, radius来绘制弦。
集群图/树状图/矩阵树图
集群图用来表示包含和被包含的关系。如学科的细分,类的成员方法等。它会生成树状的结构,且树上每个叶子节点的深度相等。在层级结构上是较特殊的一种。通过d3.layout.cluster()初始化,V4.0中包含在hierarchy模块中,通过d3.cluster()初始化。相对上面的3种图,构造较为简单。可以通过简单地读取JSON格式数据构造。
cluster(root)构造cluster树状结构。cluster.nodes方法运行簇布局,返回节点数组。links(nodes)通过指定节点数组,返回节点间的关系。每个节点都是具有两个属性source, target的对象。sort方法可以指定节点的排序方法。separation([separation])使用指定函数节点间距,通常可以根据深度大小响应调整间距,如return (a.parent == b.parent ? 1 : 2) / a.depth。此外还有size, nodesize, value等方法。
层级图中树枝的曲线绘制通常使用贝塞尔曲线,通过d3.svg.diagonal()构造。最经常用在node-link类型的图中。diagonal(datum[, index])根据datum返回path数据字符串。diagonal.source/target([source/target])分别用来设置曲线的起点和终点,且接受函数作为输入参数。projection[projection]()方法修改diagonal的映射方向,以返回[x,y]的函数作为输入参数。在V4.0版本中作为hierarchy的一部分,被移除。
d3的请求API中提供了对JSON格式数据的请求。在集群图数据较复杂时(实际上其他类型的图也会遇到数据需要从外部导入的情况),通过d3.json引入外部文件也可以轻松生成图表。
树状图和集群图一样从属于层级图(hierarchy)的范畴,区别在树状图的叶子结点深度不都相同。同样的有树布局d3.layout.tree。用法和cluster几乎完全一致。这里从略。
矩阵树图是用大小矩形表示树的节点,并面积大小表示节点从属关系和重要性。d3.layout.treemap()提供矩阵树图布局构造。links, children, value方法设置布局如何读取链路/子节点/值信息。sort方法用作节点排序,size方法设置布局展示范围,padding设置矩形间隔,默认为0。round方法设置约成的像素数,减少锯齿出现。sticky方法可以使得矩阵树在变形时保持比例,mode方法用来设置矩阵树的布局模式。ratio设置矩形长宽比,默认为黄金比例。V4.0版本中,去掉了round,sticky和mode。通过tile方法设置矩阵树布局模式,且有更多模式可以选择。
捆图
捆图几乎都是和其余布局一起使用的。用来计算节点见的路径。在V4.0版本中已经取消。V3.x中,捆图布局只有两个函数d3.layout.bundle()和bundle(links)。前者创建捆图布局,后者根据links数组的source和target计算路径。通常在使用时,通过集群图、打包图、分区图、树状图等等计算出节点位置,再用捆图计算连线路径。捆图需要的links数组可以通过其他布局的links方法轻松得到。
打包图
打包图用来表示包含和被包含的关系,同时通过大小表示相互的权重大小。通常用圆套圆的样子呈现。相较层级图更强调包含的关系。与它类似的还有treemap矩形树。将层级展开后,还可以用来创建气泡图。
通过d3.layout.pack()构造,pack(root)实例化,nodes方法返回节点,links方法返回链路信息,sort方法用来为同级节点排序。这些方法和cluster及tree是很相似的。区别是nodes中多了r计算半径,links很少使用。size方法和radius分别设置展示范围和最小圆半径,padding指定相邻圈间的大概填充,默认为0。在V4.0中,改进了画图算法。
分区图
分区图用图形的面积和依附关系表示层级和层级间的从属关系。图形可以是矩形,圆环等等。通过d3.layout.partition, d3.partition()初始化分区布局,partition(root)加入数据,通过partition.nodes(root), partition.link(root)获取分区节点和分区链路。partition.children()设置孩子访问器。同其他布局,partition有sort, value, size等方法,分别用于设置是否排序,如何获取value和布局范围[width, height]。V4.0中将层级的通用方法放在hierarchy中,增添了round([round]), padding([padding])方法。
在使用原型分区图的时候,可以通过size()方法和arc的innerRaidus, outerRadius方法巧妙实现。size([Math.PI*2, radius*radius])可以保证相同比重的区域面积相等。
地理图
地理图相较此前的图表要复杂许多。展示地图边界需要用到GeoJSON格式的数据,数据获取参见中文教程。绘制地图需要投影函数,类似于我们之前介绍的布局,将3维的经纬度转成2维平面内的横纵坐标。d3.geo.projection(raw)可以自定义一个投影函数,不过通常都是使用现有的投影函数。通过projection(location)来映射位置,输入经纬度返回横纵坐标。Projection本身还提供了invert, rotate, center([longtitude, latitude]), translate, scale([scale])等方法,类似于比例尺。clipAngle和clipExtent方法会裁剪投影范围。
geo还提供了一些常见投影。albers()是conicEqualArea()投影的别名,默认以美国为中心,albersUsa()用来绘制美国地图,azimuthalEqualArea()方位角等面积投影(经纬线绘成的区域等面积),azimuthalEquildstant()方位角等距投影(投影点到投影中心和到大弧距离等比例)。ConicConformal()兰伯特等角二次曲线投影地球为一个锥形,parallels方法可以设定投影的标准平行线为特定的二元纬度数组。conicEqualArea()是一个等区域的投影,保留了地理特征,它也有parallels方法。conicEquidistant()等距离的投影,同上。equirectangle()方法是正方形投影,经纬度类似光栅效果。geoGnomonic()方法是个方位角投影,它投射大圆(赤道)为直线,将半球投射在切平面上。mercator()是最常用的墨卡托投影,将经纬度投射在和地球相切或相割的圆柱体表面,有面积大小的失真。orthographic()投射点位于无穷远,用于投射半球,多用于卫星摄影。。tereographic()方法,立体投影。transverseMercator()方法是横向墨卡托投影。另外通过d3.geoProjection和d3.geoProject-ionMutator方法可以设置和修改自定义的projection。
显示地理数据需要用到d3.geo.path。它通过读入GeoJSON数据,生成SVG字符串或直接渲染在Canvas上(V4.0)。d3.geo.path()可以创建一个地理路径生成器。path的projection方法指定投影类型,除了上述的投影函数,还可以自定义接受经纬度返回横纵坐标的函数。path(object[, args])可以生成标点,多标点,边缘,多边形,地理对象,特写等许多地理对象。椭圆类型也支持,以用来绘制球形轮廓。path对象有许多方法,area(object)计算区域面积,bounds(object)返回区域盒模型区域,centroid(object)返回区域中心,多用来插入文本。path.context([context])指定path渲染内容,context必须实现一些CanvasRenderingContext2D的方法。path.pointRadius([radius])设置标点的半径。
还有一些常用的geo绘图对象,如circle,V4.0中通过geoCircle()构造,有center, raidus, precision几种方法,分别制定圆心位置,半径和精确度。graticule对象用来绘制经纬线的网格图,表现出投影的转换。通过geoGraticule()(同样是V4.0中),extent, extentMajor和extentMinor方法设置网格范围。step设置步长,同样有stepMajor和stepMinor两种方法,precision方法设置精度。graticule的lines()方法给出线型GeoJSON数组,数组各项对应每一条经纬线,outline()方法给出整个网格图的GeoJSON多边形对象。
GeoJSON是一项国际标准,用来编码大量地理数据。GeoJSON支持点、线、多边形、多点、多多边形几种地理形状。整个内容用FeatureCollection包裹起来。type中指定featureColelction,在features字段中加入地理对象,每个地理对象由type, geometry, properties几部分组成,分别表示类型,地理信息和额外信息。geometry里type和coordinates分别表明类型和系列点。TopoJSON对GeoJSON规范做了简化,如使用整数等,在D3中使用TopoJSON较多。
注:mapshaper可以帮助简化GeoTopo文件,做GeoJSON和TopoJSON间的转换
直方图
直方图多用来可视化离散的序列数据,或用来描述分布。通过d3.layout.histogram()构造,histogram(data)初始化,它将数据装在一个个组中(bin),容器有x0和x1两个属性确定容器的上限和下限。value([value])方法用于设置value域的预处理器,类似之前提到的各图的布局。domain([domain])方法用来限制输入数据的范围,thresholds([count])用来设置分组的界限。此外,还有一些预设方法将值组织在各组中。V3.x中,通过range方法限制输入范围,通过bins方法设置分组数/界限,且有frequency方法指定统计个数或是概率。
堆栈图
堆栈图用于描述多组数据的堆叠变化(连续和离散),如产品间随时间变化的销量组成展示。通过d3.layout.stack()构造布局,stack(layers[, index])读入堆叠数据,生成的布局有x, y, y0三个属性。values([accessor])方法设定获取值的方法,offset([offset])方法设置生成布局的方式,order([order])指定堆栈排序方法。x([accessor])和y([accessor])方法设置x和y轴的数据来源。V4.0中将x和y方法替换成了keys方法。
请求API
对于小数据集,可以将它硬编码到脚本内,或通过数据属性嵌入到DOM中。对于大数据集,最常用的方法是通过XMLHttpRequest(XHR)加载数据到浏览器,这允许异步加载数据,比JSONP更方便。d3的请求API就建立在XHR的基础上。
d3.xhr(url[, mimetype][, callback])是通用的构造方法,还可以通过header方法,mimeType方法,responseType方法等设置请求属性。send(method[ ,data][, callback])方法使用指定方法分发请求,在get和post时有专门的get和post方法。此外abort方法中止请求,on方法监听beforesend, progress, load和error事件。V4.0中,xhr部分更名为request。
特殊情况下,d3有许多简便方法。d3.text(url[, mimetype][, callback])用来创建文本文件请求,请求以GET方法立即分发。callback中可以使用error和response文本,下同。d3.json(url[, callback])通过制定url创建JSON请求。d3.xml, d3.html, d3.csv, d3.tsv也是一样的情况。tsv的mimeType为text/tab-separated-values。
随机数API
d3提供了产生特定分布随机数的若干API。包括d3.random.uniform等。uniform方法产生均匀分布随机数,normal方法产生正态分布规律的随机数,bates, irwinHall, logNormal方法分别产生贝兹分布、Irwin-Hall分布和对数正态分布规律的随机数。使用时,先通过这些方法构造生成函数,再使用函数产生随机数。
行为API
V3.x和V4.0的行为(Behavior)包括两种,drag和zoom。在V4.0中分别拆分成dragging和zooming两部分。drag行为通过d3.behavior.drag()注册,可以通过selection.call(drag)来为选择集绑定拖拽行为。通过drag.on(type[, listener])监听dragstart, drag, dragend三种事件,drag事件可以提供行为的x和y坐标及dx, dy改变量。d3.origin([origin])方法设置drag行为的原位置accessor。绑定drag行为的元素的一些native事件会被阻止,如click, mousemove等等。
V4.0中的container()方法可以指定拖拽的容器,从而影响event.x等。filter([filter])方法指定阻止和不阻止的事件。同时,origin()方法改为subject()方法设置被拖动元素的种种属性。drag事件有target, type, subject, x, y, dx, dy, identifier, active, sourceEvent属性可以使用。
zoom行为由d3.behavior.zoom()来构造,通过translate()设置位置,scale()方法指定当前缩放比例,scaleExtent()方法指定缩放比例范围,center([center])手动指定缩放中心,size([size])设定观察尺寸,x([x])和y([y])方法分别设置x和y方向上的缩放比例。类似于drag,zoom可以监听的事件有zoomstart, zoom和zoomend,还可以通过zoom.event(selection)在选择集上触发zoom事件。V4.0中添加了scaleBy, translateBy, extent等方法,zoom event提供translate和scale两个属性供用户使用(V3.x),V4.0中提供target,type,transform,sourceEvent四个属性。
颜色API
颜色是可视化中必不可少的一部分。也是d3模块中的重要组成部分之一。D3提供多种颜色空间的表示,包括RGB,HSL,LAB和HCL,并可以实现格式的转换和颜色的操作。d3.color(specifier)可以根据css样式构造d3颜色类型。color.rgb()返回rgb格式颜色对象,color.toString()返回颜色对象的css格式。另外V3.x中,color对象的brighter, darker方法应用在rgb,hsl,hcl,lab中。V4.0版本中,color对象还有opacity()和displayable()方法返回颜色透明度和硬件是否支持。同时,cubehelix格式的颜色也在4.0版本中支持。
实际使用时,颜色插值器interpolate也回应常用到来获取两个颜色中间的某个值。d3.interpolateRgb()和d3.interpolateHsl()分别处理rgb和hsl的插值计算。interpolate()可以处理树枝和字符串间的插值。使用时,先通过interpolate(a, b)构造一个插值器函数,函数的定义域为[0,1],从而通过不同的输入参数获得不同中间值。
更多
除了上面提到的官方wiki和中文手册,还有作者本人写的种种演示实例,在关于D3.js在国内还没有很权威的入门教程,ourd3js算是写的比较好的d3入门和进阶教程了,在里面还有许多有助于d3学习的其他网站。
Sass
Sass是一种适合程序员使用的CSS预处理器。它预先约定了许多CSS的书写手法,为之赋予了可编程的能力。Sass使用Ruby语言实现,安装使用时需要预装ruby和gem,再通过gem install sass安装Sass。Sass可以将.scss文件编译成普通的CSS文件。
编译时,--style选项可以指定nested,expanded,compact,compressed几种风格,默认为nested,在生产环境下一般使用compressed。--watch选项可以监听.scss文件,在源文件改动时。自动编译成css文件。
注意:Sass可以编译后缀名为.scss和.sass两种css文件,两者的格式是不同的。前者更像传统的CSS,使用大括号区分层级;后者使用缩进,且不使用分号。具体可以见参考。
约定
Sass自带交互shell,通过在命令行输入sass –i进入,便于开发者进行测试。
Sass中使用/**/ //来注释,其中单行注释会在编译时移除。Sass允许使用变量,变量以$符号开头,使用时也需带上$。变量有number (1, 2px),string ("foo", 'bar', baz),color (blue, #123456, rgba(0,0,0,255)),bool (true, false),null (null),list (1em 0em 1.5em, Arial sans-serif serif),map ( (key1: value1, key2: value2) )几种类型。为变量赋值时,支持使用!default表示默认值。在变量名中甚至可以通过#{…}的形式嵌入变量名(这点像PHP)。Sass允许在代码中使用算式和嵌套。在嵌套时,还可以使用&算符表示父元素。
$var = 2;
$hover = #0f0;
$fonts = Arial sans-serif;
div {
font-family: $fonts;
h1 {
color: red;
right: $var * 10%;
}
&:hover {
color: $hover;
}
}
Sass一大精髓就在于代码重用上。使用@extend可以继承某个选择器的样式,使用@mixin定义css中的mixin(类似于函数),通过@include使用定义好的mixin,更加灵活的是mixin支持输入参数。类似的@规则还有@import引入sass或是css文件,@media表示当前媒体,它们都支持嵌套。@at-root,@debug,@warn,@error等参见文档介绍。
@mixin rounded($vert, $horz, $radius: 10px) {
border-#{$vert}-#{$horz}-radius: $radius;
-moz-border-radius-#{$vert}#{$horz}: $radius;
-webkit-border-#{$vert}-#{$horz}-radius: $radius;
}
.class1 {
border: 1px solid #ddd;
}
.class2 {
@extend .class1;
font-size: 12px;
}
#navbar li {
@include rounded(top, left);
}
#footer {
@include rounded(top, left, 5px);
}
另外,Sass还自带语法控制结构(有人认为这是它强于less的一点)。@if,@else用于判断,@for,@while,@each用于循环。用法如下:
$type: monster;
$i: 6;
p {
@if $type == ocean {
color: blue;
} @else if $type == monster {
color: green;
} @else {
color: red;
}
}
//使用to也可以
@for $i from 1 through 3 {
.item-#{$i} { width: 2em * $i; }
}
@each $animal in puma, sea-slug, egret, salamander {
.#{$animal}-icon {
background-image: url('/images/#{$animal}.png');
}
}
@each $header, $size in (h1: 2em, h2: 1.5em, h3: 1.2em) {
#{$header} {
font-size: $size;
}
}
@while $i > 0 {
.item-#{$i} { width: 2em * $i; }
$i: $i - 2;
}
最后,Sass还支持数量繁多的预定义函数和用户自定义函数。如颜色函数lighten(), darken(), grayscale(), complement(), opacity(), 字符串函数,数字函数,list函数等等
lighten(#cc3, 10%) // #d6d65c
darken(#cc3, 10%) // #a3a329
grayscale(#cc3) // #808080
complement(#cc3) // #33c
@function double($n) {
@return $n * 2;
}
#sidebar {
width: double(5px);
}
Compass
Compass是建立在Sass之上的一个工具包。它和Sass的关系相当于jQuery和Javascript,Rails和Ruby,Django和Python,express和nodejs,是Sass的一个重量级的应用。Compass封装了常用的各种模板,使得在Sass的基础上开发CSS效率大大提高。
Compass也是通过gem install来安装,安装完成后通过compass create project创建工程,文件夹下包括配置文件config.rb,和scss,stylesheet两个子文件夹。Scss文件编辑完成后,使用compass compile编译,还可以通过output_style,force等参数修饰,Compass也有watch命令。
Compass将css设计中最常用以及最繁琐的部分通过预设的模块尽量封装了起来。包括reset,css3,layout,typography,utilities以及一些额外的helper函数。
不过,由于Compass的功能和bootstrap这种css库功能有重叠(不过是更加开放灵活,且和Ruby绑定而已),让人犹豫它的定位。Compass自2014年起不再维护。
ES6新特性
ECMAscript2015年5月份发布了第六版新标准。引入了一些更加方便的操作方式和一些突破性的新概念。以下是ES6的一些新特性。
let用于在代码块中声明临时变量。尤其在for循环中最为常用。const用来声明常量,具有块级作用域。不能重复声明,复制无效。
includes()返回是否查到子串,startsWith()返回子串是否在开头,endsWith()返回是否在结尾。string对象新添加repeat函数,返回原字符串重复n次的结果。
支持在字符串中使用模板,以${}的形式添加。类似C++中的格式化字符串。模板字符串可以支持多行。tag函数处理标签模板,将模板字符串分解成数组的形式。string.raw作为模板开头,可以使模板字符串“无视”特殊字符。
isNaN和isFinite函数判断是否为数字和是否无穷。isInteger()判断一个值是否为整数。
Math新增静态方法。trunc()除去小数部分,sign()判断是正数、负数或0,cbrt()计算立方根,hypot()返回参数平方和的平均数等等。Expm1返回ex-1,log1p返回x+1的自然对数,log10,log2类似。还有sinh, cosh, tanh, asinh, acsh, atanh等三角函数方法。
Array新增from方法,支持从类数组对象和可遍历对象中创建数组,可接受第二个参数,作用类似于数组map方法。可用于计算含有长编码字符的字符串。实际上,有length属性的对象都可以通过该方法转为数组。新增of方法,弥补Array()构造函数的不足。为输入的值创建数组
新增find和findIndex方法,输入参数为回调函数,分别返回第一个true的成员与其index。fill方法用于使用给定值填充数组,接受第二和第三个参数,指定填充范围。
entries(), keys(), values()分别返回键值对,键名,键值的迭代器。类似于C++的iterator。
在写入变量或函数到对象的属性或方法时,允许省去键名。属性名允许使用中括号加表达式的方式定义,可以用在大括号的方式定义对象中。如var obj = {[1 + 2]: 3};
Object新增is方法,作用类似===。不同的是+0和-0是不等的,NaN和NaN是相等的。新增assign方法,可以将source所有可枚举属性赋值到target中,source和target必须都为对象。第一个参数为目标对象,后面的参数都是源对象,同名属性会被覆盖。
Symbol类型是一种原始数据类型,表示独一无二的ID。不可以与其他类型值运算,可以转为字符串,通过Symbol()初始化。可以加输入参数对Symbol进行描述。
proxy对象用来为一些基础操作定义用户自定义行为。target作为被代理的对象,不可拓展性和不可修改属性的不变量会被代理handler拦截。使用proxy可以做无操作转发,默认值设置、验证处理等。handler对象有许多方法可以使用。
函数新增默认值,使用类似C++,Java。函数的输入参数可以用...values表示剩下的所有不定参数。这些不定参数将组成数组储存在values中。类似的,拓展运算符…支持向函数输入参数组成的数组
箭头函数是使用=>语法的函数简写体。和C#, Java 8, CoffeScript类似。同时支持表达式体和语句体。用法:v=>v+1, (v, i) =>{v += I;};箭头函数的this对象与其上下文代码共享。这一点与函数体不同。同时,箭头函数不可以当作构造对象,也不能使用arguments对象。
函数绑定运算符,::作用和bind类似,将左边的对象作为上下文环境绑定到右边的函数上去。let log = ::console.log等同于var log = console.log.bind(console).
尾调用优化。当函数最后一步操作为调用另一函数时,称为尾调用。尾调用优化即只保留内层函数的调用帧,删除外层函数调用帧节省内存。
数据结构Set是成员唯一的数组。可以使用array来初始化,如new Set(array). size方法可以返回当前set集合元素总数。有add, delete, has, clear完成增删改查的工作。Set可以通过array的from方法转为数组。keys, values, entries, forEach方法用于遍历成员。
WeakSet是弱化版的Set。成员只能是对象。只有add, delete, has方法。没有size属性,也不能使用forEach遍历成员。
数据结构Map是无序数对组成的集合。方法与Set类似。有size, set, get, has, delete, clear等用法。其中set用法返回自身因此可以链式调用。Map同样有WeakMap子对象。它只接受对象作为键名,键名所指向的对象不计入垃圾回收机制。只有get, set, has, delete方法可以使用,
迭代器对象。和C++中的迭代器类似。它为各种可迭代的数据结构提供一个简便的同意的接口。同时可以在for of循环中使用。next方法返回value和done两种信息。可迭代数据结构都必须事先名为Symbol.iterator的方法,位于Symbol.iterator属性上面。调用该属性就可得到遍历器。有些操作会隐式调用iterator接口。如拓展运算符..., Array.from()等。可以通过修改Symbol.iterator属性改变原生具备该接口的数据结构的迭代表现。对了next方法外,迭代器对象还可以部署return方法,用于在循环退出前,进行注入释放资源等操作。for of循环等价于for in循环的迭代器版。
函数生成器Generator,用于遍历函数的内部状态。形式上Generator函数是个普通函数,不过function命令与函数名间有*符号。函数体内使用yield语句定义不同内部状态。其余同iterator,有next方法,返回具有value和done字段的数组。yield后面不仅可以跟数据,还可以跟代码片段。yield语句本身并没有返回值,可以通过next函数输入作为其返回值。for of循环同样可以用来遍历Generator函数。throw方法用来捕获函数体外错误。
Promise对象用来传递异步操作信息。状态不受外界影响,有pending, resolved, rejected三种状态。只有操作结果会影响这个状态,这个对象便于控制异步操作。用法为先通过构造函数创建异步操作块。通过resolve和reject将操作结果传递给promise使用then绑定的处理函数。then方法返回的是一个新的Promise实例,因此支持链式调用。catch方法是then方法的特例,用于捕获异常。
Promise的all方法将多个Promise实例封装成1个,实例都通过才算通过。race方法根据第一个改变状态的Promise实例做判断。resolve方法可以将现有对象转为Promise对象,不具有then方法的对象,则返回一个状态为resolved的Promise对象。reject方法类似,不过实例状态为rejected。
async函数是对Generator函数的改进,内置执行器,使用await代替yield,语义清晰,且之后可以跟Promise和原始类型的值。
Class是ES6提供的更靠近传统语言的写法。Class之间可以通过extends实现继承,但在构造函数必须调用super方法。内部可以使用get和set关键字对属性设置读写函数。同时Class接受Generator函数,写法 * [Symbol.iterator](){}; for of循环会调用这个遍历器。static关键字用来定义静态方法,通过类来调用,且可被子类继承。
类有修饰器decorator,通过@decorator使用在类上方。可以在编译时改变类的行为。为类添加属性或是方法。decorator接受目标函数,属性名,描述对象三个参数。
Module也是ES6引入的新特性。主要有export, import命令组成,和CommonJS设计的规范十分类似。分别用export{a,b,c} from xxx和import {a,b,c} from xxx。若想为输入的变量重新取名,可以用as关键字。可以用*代替模块名做整体引入。module命令也可以代替import完成整体引入。用法和import类似。export default命令指定默认输出,import时可以不带大括号,为导出的内容取任意名字。模块间允许继承。
杂项
Markdown
Markdown的目标是易读易写,它让人专注于文章的内容而不是格式与排版。一篇使用markdown写作的文档,可以在任何文本编辑器内打开。从而带来的优点是,它可以通过git来进行版本控制和多人协同。Markdown更厉害的一点是,在插件的帮助下,可以书写数学公式。Markdown兼容HTML语法,且会自动转义HTML特殊字符。
Markdown段落由一个或多个文本行组成,前后要有一个以上的空行。从而Markdown允许段落内的强迫换行。
段首的#数目表示标题阶数。#空格后的内容为标题名称。区块引用在内容前加上>和空格,且支持嵌套引用。用*, +或-表示无序列表内容,数字接英文句点表示有序列表,后面亦要加空格。列表下的段落必须缩进4个空格或1个制表符。列表下的代码区快需要缩进两次。
代码区块的写作需要缩进4个空格。区块内的特殊字符会自动转成HTML实体。使用3个以上的*, -或_可以创建分割线。[name](link)可以创建行内链接。[name][id]可以创建参考链接,在文段的任意位置,通过[id]: url (some text)和链接创建联系。链接辨别标签不缺分大小写。在id缺省时,会自动用name当作链接标签
使用*或-包裹字符可以实现强调的效果,此时*和-需紧贴字符。使用反引号`包裹内容实现行内代码。若代码中也有反引号,可以用多个反引号开头。
可以插入图片,和链接类似,也有行内和参考两种形式。同时,markdown还会自动将<>内的网页和邮箱地址封装成链接的格式。关于表格的写法,参加链接。Markdown还支持反斜杠转义特殊字符。
### github里的readme.md就是用markdown写的。
JSONP & CORS
同源策略由NetScape网景公司提出。现在所有支持JS的浏览器都会使用这个策略。这个策略的意思是,只有相同域名、协议、端口下的脚本才会被执行,避免其他网页对本网页的非法篡改。因此,JS脚本不能跨域发起请求。除了使用Proxy server外,可以通过JSONP在服务器端支持的情况下,实现跨域访问。
JSONP(JSON with padding)并不是一种协议,而是解决办法。它允许服务器端集成Script标签,返回客户端,并以js callback的形式实现跨域。它的原理主要利用了<script>标签对JS脚本的动态解析实现。callback在客户端注册,并放在url中传给服务器;服务器先生成JSON数据,再以JS的形式调用与callback同名的函数,并将JSON数据以入参的形式返回给客户端。从而实现跨域请求。
下面是向一个支持JSONP请求的服务器发送跨域资源请求的代码,值得学习:
function getJSONP(url, success) {
var ud = '_' + +new Date,
script = document.createElement('script'),
head = document.getElementsByTagName('head')[0]
|| document.documentElement;
window[ud] = function(data) {
head.removeChild(script);
//`success` can be undefined
success && success(data);
};
script.src = url.replace('callback=?', 'callback=' + ud);
head.appendChild(script);
}
注1:JSONP跨域请求需要服务器端支持,且只支持GET请求。
注2:jQuery支持JSONP,通过$.getJSON或其他基于$.ajax()的方法来加载JSON数据。
CORS(Cross-origin resource sharing)跨域资源共享标准允许浏览器向跨域服务器发送XMLHttpRequest请求,克服了同源限制。CORS是新标准,需要浏览器和服务器同时支持,目前所有浏览器都支持此功能。整个CORS通信过程,由浏览器自动完成,用户在发起跨域AJAX请求时与同源时没有区别。浏览器发现跨域后会添加额外头信息,实现了CORS接口的服务器可以完成跨域请求的响应。CORS实现的重点在服务器端,具体内容可以学习阮一峰的博客。
依赖注入
这个概念在学习NodeJS和AngularJS等时,都有出现,简单来讲,依赖是指在类或函数A里需要用到类或函数B. 依赖注入即非自己主动初始化依赖,通过外部传入依赖。这样可以实现解耦和方便mock测试。更多的分析参见链接。
语法糖
语法糖(Syntactic sugar),也译为糖衣语法,由英国计算机科学家Peter J. Landin发明的术语,指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更便于程序员使用。语法糖并没有为计算机语言添加新功能,而是给程序员提供了更使用的编码方式。如C语言中用a[i]表示*(a+i)。
函数式编程
将函数(动词)视作和变量(名词)一样的地位,就可以称为函数式编程语言。极端如Java,纯粹的面向对象编程,不允许函数单独出现,必须包含在名词当中;或是某个虚幻的函数式语言圣地,不存在名词,均使用函数返回值来表现。名词王国的死刑与它很好的译文出色的介绍了这些的利与弊。
IIFE(立即执行函数)
方法中定义的属性和方法都置于内部作用域。IIFE利用此实现私有化,同时,在function定义后的()会被视为分组操作符,和之前的函数没有逻辑联系。但是,将function expression部分用()包裹后,解析器不会将之作为func。ion declaration解析,消除了歧义。而后的()就会被视为调用之前的function expression。
类似的,使用表达式组合同样可以避免此歧义。如0, function(){}() !function(){}()甚至new function(){}。同时,推荐将整个表达式用()包裹,增加可读性。原文给出了一个特别好的例子来说明变量私有化。
同时,因为没有名字,IIFE还可以避免污染当前作用域,实现类似模块的效果。原文也有例子展示。
注:链接里的是译文,原文在此。
Nodejs中的Stream
使用流编程的概念在Unix时代就已经出现。Node中的stream模块完成的功能也与unix类似。两者的基本管道操作符分别是.pipe()和|。Node借助流可以将接口部分分割成多个可重用的部分。
pipe是stream中输入输出的实现方法,按照src.pipe(dst)的形式使用。Node中的流可以分为readable, writeable, transform, duplex, classic几种。readable流可以产出数据,调用pipe方法传送到writable, duplex, transform流中,也可以通过read方法直接消耗。writable流只能流进不能流出,通过定义一个_write(chunk, enc, next)将readable数据写入,通过调用write()方法可以直接向流中写东西。
transform流和duplex流都可读可写。区别是transform流并不保存数据,只处理流经它的数据。classic流是一个古老的接口,有readable和writable两种。
Crypto
Crypto是NodeJS的一个加密算法库,提供了加密解密验证等功能。它基于OpenSSL的基础上开发,提供了一系列的哈希算法和签名验证等方法的封装。
尾注
本文列举了十余项前端技术,涵盖了框架,包管理,包构建,模块规范,任务管理,可视化等方面。在测试框架,socket编程等方面还有欠缺。
另外,网页的结构灵感来自于backbone.js, underscore和zepto的文档网页设计,个人认为这种设计清晰简洁,没有一些“没必要的废话”。
最后祝你,身体健康。
2017/2/2